
The main goal of OpenArabic mARkdown is to provide a simple system for tagging structural elements in premodern and early modern Arabic texts that are being prepared within the framework of the OpenArabic Project. The use of OpenArabic mARkdown will allow one to engage in the computational analysis of classical Arabic texts in the same way as more complex and time-consuming tagging schemes (like TEI XML); OpenArabic mARkdown will also facilitate the conversion of the large volume of Arabic texts into TEI XML, which is now the standard format for digital editions. In principle, OpenArabic mARkdown does not require any special editor, but the current implementation relies on EditPad Pro, which supports right-to-left languages, Unicode, and large files. However, it is the support of custom highlighting and navigation schemes that makes this text editor particularly convenient for OpenArabic mARkdown.
Detailed Description
Using OpenArabic mARkdown in EditPad Pro
EditPad Pro is a commercial text editor for Windows. It can be used on Mac and Linux through some virtualization solution (for example, Parallels or Fusion on Mac, or Wine on Linux). You can download a fully functional trial version to try OpenArabic mARkdown (it, however, will not work with EditPad Lite, a free light-weight version of the same text editor).
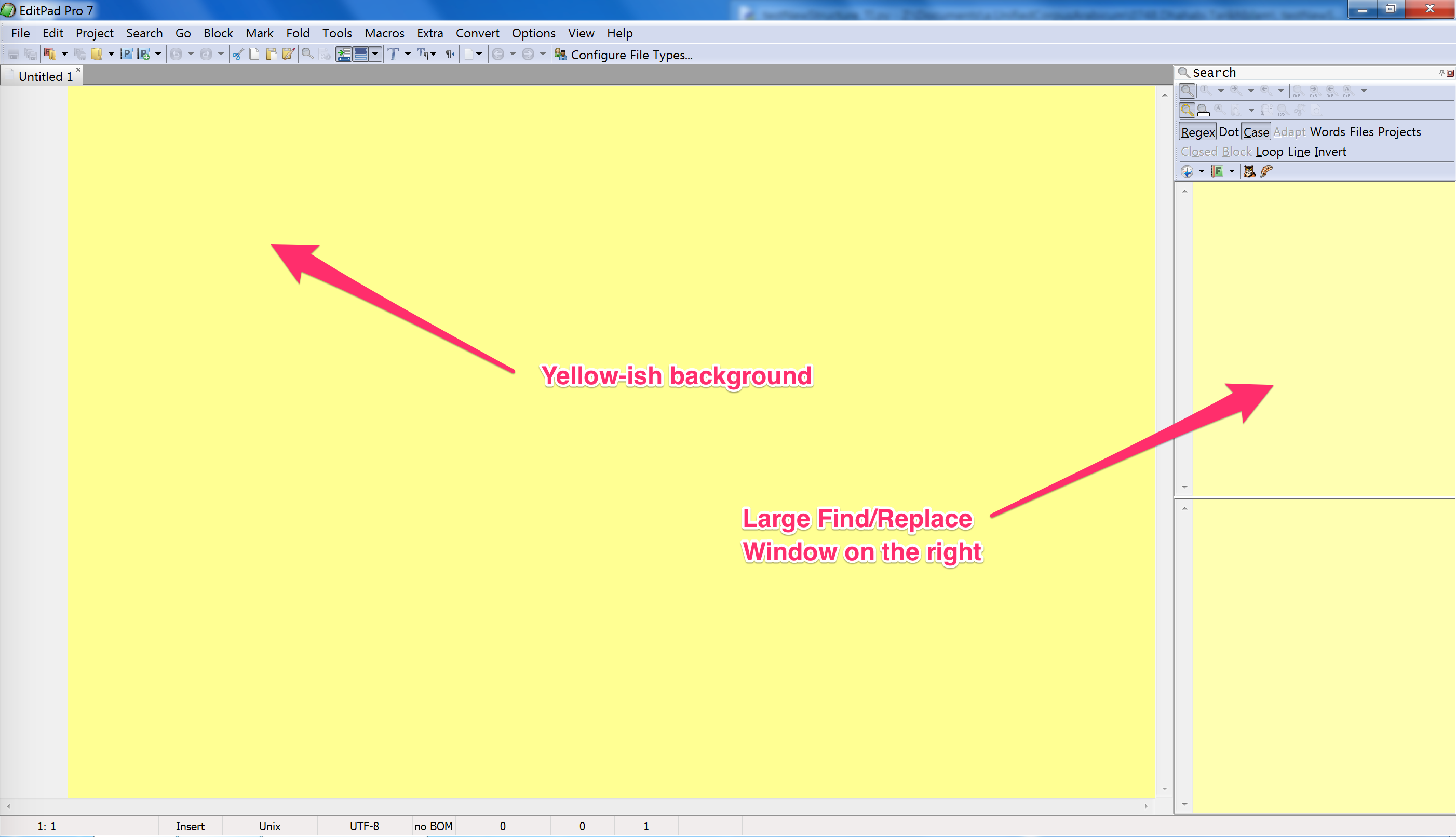
The most recent OpenArabic mARkdown settings files for EditPad Pro can be found in the mARkdown repository on GitHub. You can download the entire repository or just the *.zip file (the date is in the filename: YYYYMMDD_HHMMSS.zip). Unzip its content, and copy all the files into %APPDATA%\JGsoft\EditPad Pro 7. You will need to restart the program (use: File > Exit). If OpenArabic mARkdown settings work, the main window should look as shown below. Note the yellow-ish color of the main window and a large Find/Replace panel on the right).
In a text file, OpenArabic mARkdown is activated by the “magic value” at the beginning of the text file, which is #####ARABICA#. (In other words, the very first line of the text should consist exclusively of this value.) The highlighting scheme relies on regular expressions (RE) to color a limited number of pattern in the text.
Note: You can try test_textFile from the github repository. The file does not have an extension to avoid accidental opening in Notepad—the default text editor on Windows, which cannot handle large files. Drug-n-drop the file onto EditPad Pro to open it. The OpenArabic mARkdown should be automatically activated. (If you start a new file, you may need to reopen it after adding the “magic value”.)

General description
OpenArabic mARkdown includes structural elements and in-text elements—all are highlighted with different colors. This helps one to avoid mistakes while tagging texts, and, additionally, makes the structure of the text easily discernible to the human eye. Configured in a custom highlighting scheme, all elements are activated with regular expressions (RE).
EditPad Pro also supports folding of structural elements that span over multiple lines. This allows one to contract—or fold—the entire text into a table of content and then open—or unfold—only elements that one wants to work with.
I. Structural elements
I.1 Metadata
All texts in OpenArabic have automatically inserted metadata blocks in the beginning of the file. This metadata is collected from initial collections and is neither fixed nor vetted.
I.2.1. Source Headers
RE: ^### \|+
Headers are for the titles of main structural units, like chapters, subchapters, etc. in the text of the source. The entire header must be on one line and must include three main elements:
###— three hashtags at the beginning of the line;|— pipes, whose number corresponds to the level of a header;Header— the text of a header (followed by\n, “new line” character)
### | First Level Header (red)
### || Second Level Header (orange)
### ||| Third Level Header (yellow)
### |||| Fourth Level Header (green)
### ||||| Fifth Level Header (blue)
A gif-image below shows how headers get highlighted with different colors when tagged properly. Colors follow the rainbow spectre (they stop changing after Level V):

I.2.2. Editorial Headers
RE: ^### ===
Many books also include sections written by editors. These sections are not parts of the actual source and they must be tagged distinctively so that they could be easily excluded from automated forms of analysis. The tag can also be used for any “in-edition” information, which is not relevant to the actual text of the source (for example, there are often lines saying this is such and such volume of a such and such book—these can be tagged as “editorial headers”). The tag is added in the same manner as source headers and is: ### === (at the beginning of the line).
I.3. Information Units
RE: _multiple_
Most of the texts that I have worked with so far have a very clear structure (chapters > subchapters > subsubchapters, etc.), where the lowest level structural units (subchapters or subsubchapters) are made of “information units,” such as biographies in biographical collections, descriptions of events in chronicles, and dictionary entries (on lexical items, names, toponyms, book titles, etc.)
Using OpenArabic mARkdown, one needs only to mark the beginning of each information unit. Each unit can be marked with either a simplified or full tag. Simplified tags are short, which makes them ideal for manual tagging. Simplified tags are, however, ambiguous. Full tags are more readable and source independent. Full tags are particularly important when information from multiple sources is processed at the same time.
OpenArabic mARkdown has been first developed for biographical collections, chronicles, bibliographical collections, and dictionaries of different types. In most cases, these sources contain one type of information units and in such cases one can use only one type of tag ### $ [information unit], which can be later converted—using find/replace—into corresponding full tags. Below is the description of used tags.
I.3.1 Dictionaries
RE: _multiple_
Arabic dictionaries usually include information units of the same types, so one simplified tag—### $ [a dictionary item]—is sufficient. The full tags depend on the nature of each dictionary and at the moment include “descriptive names,” toponyms, lexical items, and book titles. Tags for them are as follows:
### $DIC_NIS$ [a descriptive name entry]
### $DIC_TOP$ [a toponym entry]
### $DIC_LEX$ [a lexical entry]
### $DIC_BIB$ [a book title]
I.3.2 Biographical Collections and Chronicles
RE: _multiple_
Biographical collections often include several types of information units. Moreover, there are plenty of sources that combine features of both biographical collections and chronicles (“obituary chronicles”), so one often has to deal with a variety of information units in the same text. For this reason, the main simplified tags are as follows:
### $ [a biography of a man]
### $$ [a biography of a woman]
### $$$ [a cross-reference and/or repetition, for both men and women]
### $$$$ [a list of names]
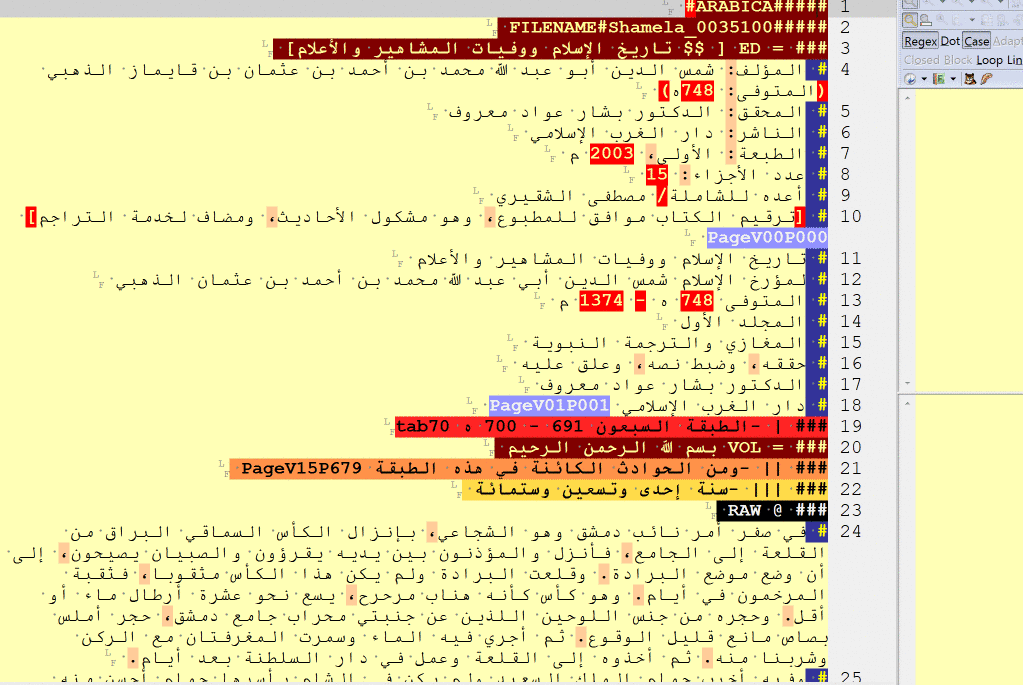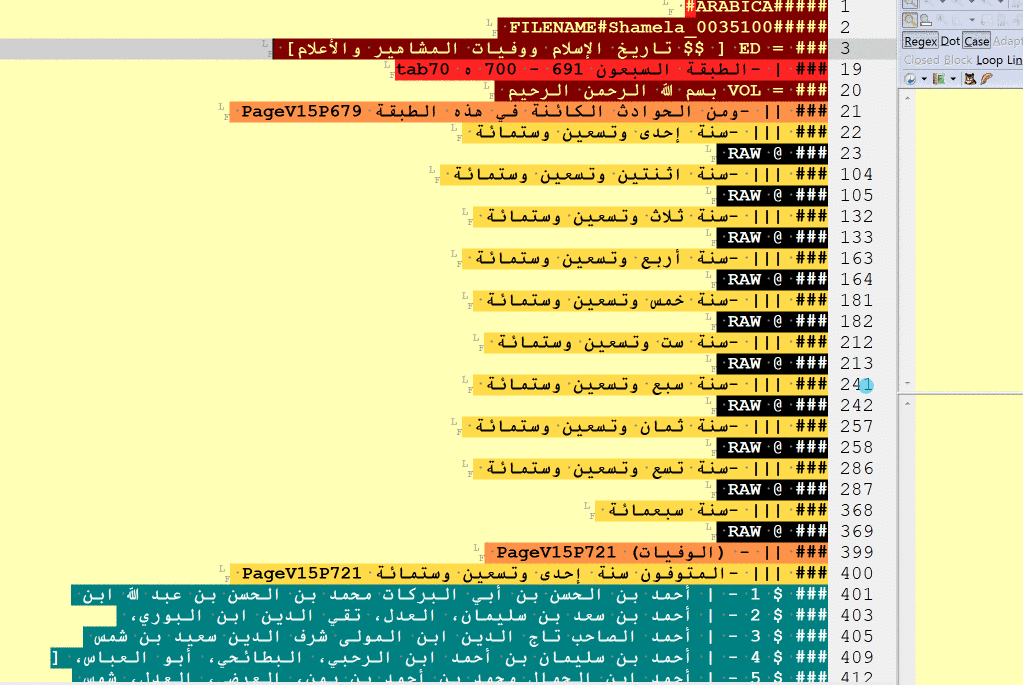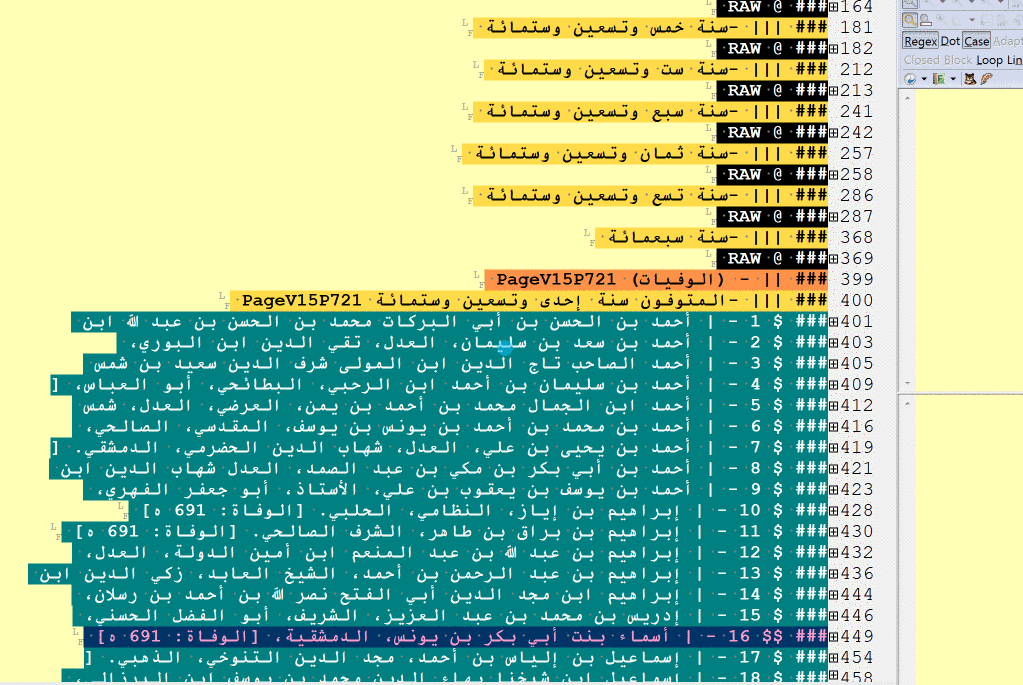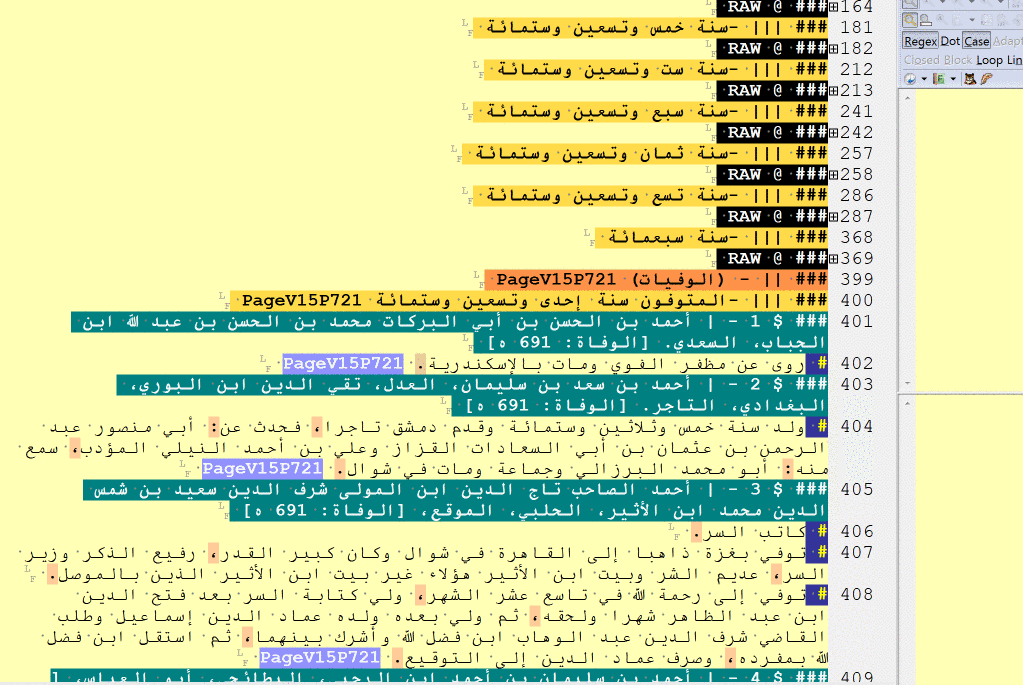
### @ [a historical event]
### @ RAW [a batch of historical events]

NB: ### @ RAW can be used to tag blocks of historical events when it is not immediately clear when one information unit ends and another begins. With these tags in place, one can return to an unfinished batch later, read it more carefully, and split properly into single units. There is also, of course, a conceptual and methodological issue with regard to what constitutes an ‘event’. For the purposes of algorithmic analysis, [the “description of an] event” is a structurally and thematically complete unit of text that describes an entity that has 5 properties: subject, predicate, object, time and place. In other words, it is something that can be grouped into categories, graphed across time, and mapped in space.
Full tags are as follows:
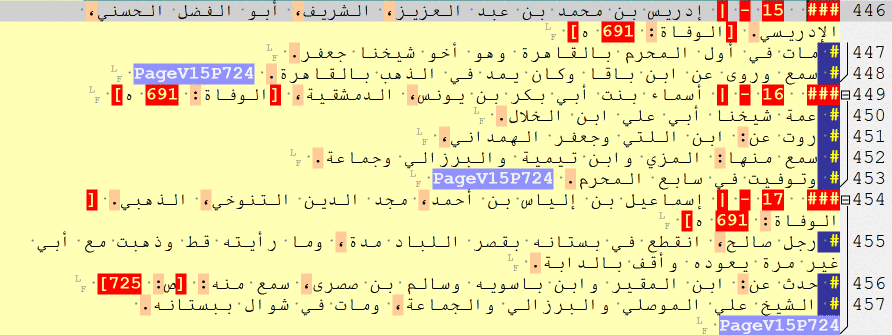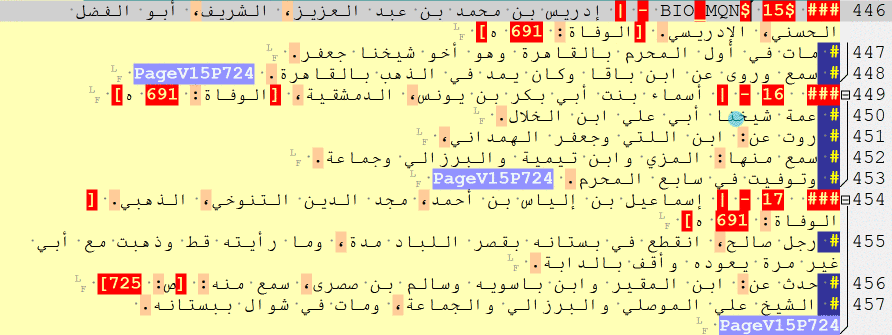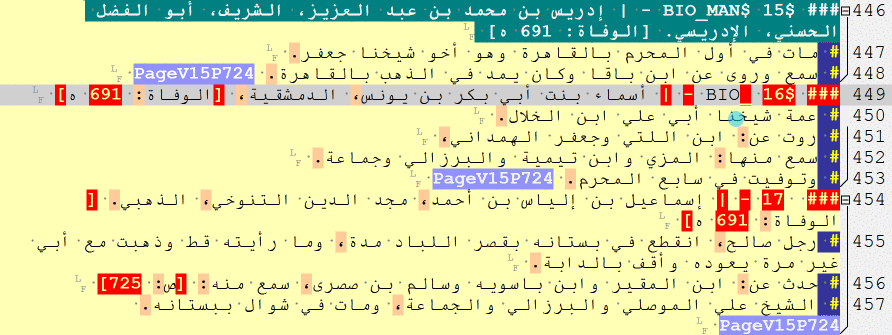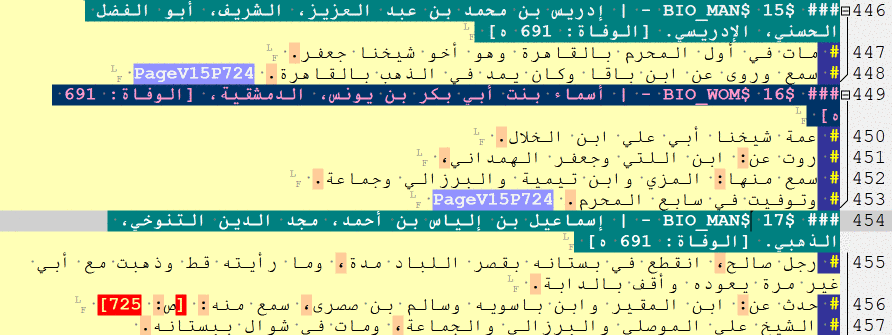
### $BIO_MAN$ [a biography of a man]
### $BIO_WOM$ [a biography of a woman]
### $BIO_REF$ [a cross-reference, for both men and women]
### $BIO_NLI$ [a list of names]
### $CHR_EVE$ [a historical event]
### $CHR_RAW$ [a batch of historical events]
I.3.3 Other types of information units
I.3.3.1 Riwāyāt units
NB: U Frankfurt Team; added: August 12, 2016; updated: March 31, 2017
Each riwāyaŧ/ḥadīṯ report should be treated as a separate paragraph: new line + # $RWY$ ; in order to mark the boundary between isnād and matn, @MATN@ tag is to be inserted between isnād and matn. Since it is not uncommon to have an evaluation of reported material, tag @HUKM@ can be used to tag the beginning of the ḥukm-statement. All three elements of a riwāyaŧ/ḥadīṯ must remain the part of the same paragraph.
# $RWY$ this section contains isnād @MATN@ this section
contains matn @HUKM@ this section contains ḥukm .
It is not uncommon that either isnād or matn is missing. In such cases @MATN@ tag still must be inserted: in the case of missing isnād, @MATN@ directly follows # $RWY$ ; in the case of missing matn, @MATN@ becomes the last element in the ḥadīṯ paragraph. @HUKM@ is optional and inserted only when there is a ḥukm-statement.

The following regular expression will help highlighting sections with isnāds (copy-paste it into the search window of EditPad Pro):
\bو?(عن|حدث(نا|ني|ت)|[اأ]نبأ(نا|ني|ت)|[اأ]خبر(نا|ني|ت)|[اأ]?نا|ث?نا|ثني)(( |\n~~)(\w+( |\n~~|\b)){1,3})
#### I.3.3.2 Doxographical units
~~NB: David Bennet; added: September 23, 2016
The following tags are section tags to be places at the beginning of a relevant section: (1) ### $DOX_POS$ for sections dealing with doxographical/theological positions; (2) ### $DOX_SEC$ for descriptions of religious groups (“sects”). These can be used equally in doxographical texts and texts that address doxographical issues among many other things.
I.3.4 Secondary divisions in chapters and information units
#### I.3.4.1 Internal subdivisions
Chapters and information units may have internal divisions that are marked either in the original editions or being introduced by a researcher. These can be tagged with # --- description either on a separate line right before a sub-unit (where description is a researchers own characterization of a unit, i.e. # --- teachers marks a section of a biography that includes the names of a biographee’s teachers)
II. In-text elements
Most of the in-text elements are already in pre-formatted texts. In most cases, you do not need to worry about them, but it is important to understand how they function.
II.1 Paragraphs and lines
RE: ^# , ^~~
In premodern Arabic texts paragraphs as units are not particularly reliable. Yet, if a certain electronic text reproduces a printed edition, it is worth preserving its division into paragraphs. Each paragraph begins with a hashtag, #.
While EditPad Pro handles large files very well, it has problems with long paragraphs (or, more correctly, lines). For this reason, long paragraphs are split into shorter lines, where each line starts with ~~ (two tildas).

III. Analytical Patterns and Semantic Tagging
III.2 Named Entities
NB: Added: April 22, 2016
At the moment these include toponyms (@TOPXX and @TXX), individuals (@PERXX and @PXX) and social/onomastic/biographical characteristics (@SOCXX and @SXX).
All tags have similar structure @ + CODE + two numbers. CODEs have two variations: 1) long (three letters) and 2) short (one letter). Triliteral CODEs are used for automatic tagging with scripts and entity lists; one-letter short CODEs are used for manual tagging and disambiguation of automatic tags.
XX, two numbers, indicate:
- the length of an attached prefix. For example, if
wa-orbi-are attached to an entity, the first number must be1, which means that 1 character from the beginning must be removed) - the length of the entity. If the entity is a bigram (Madīnaŧ al-Salām), number
2must be used (both words will be automatically highlighted).
NB: The tags have two varieties: a long one and a short one. The long one will be used for automatic tagging (the automatic tagger is in progress), while the short one will be reserved for manual tagging, as shorter tags are easier to type in manually; additionally, the conversion of an automatic tag into a manual one in the process of edition and disambiguating is more efficient by deleting two characters, rather than adding them.
III.2.1 Toponyms
- Automatic long tag:
@TOPXX - Manual short tag:
@TXX

III.2.2 Individuals (Persons)
- Automatic long tag:
@PERXX - Manual short tag:
@PXX
III.2.3 Biographical characteristics
- Automatic long tag:
@SOCXX - Manual short tag:
@SXX
III.3 Years AH
Years AH can be tagged in the following manner (where # is a digit; there must be spaces on both sides of the year tag):
YB####— a year of birth, as mentioned in a biography; for example,@YB510means that a biographee was born in the year 510 of the Islamic hijrī calendar.YD####—a year of death, as mentioned in a biography; for example,@YD597means that a biographee died in the year 597 of the Islamic hijrī calendar.YY####—any other type of year references mentioned in a text.YA####— age in years.
Leave a comment