

Chronological Coverage of an Arabic Corpus
While looking for a way to identify all biographical collections and chronicles (and, by extension, all other texts that offer data for time-series analysis) in a collection of 0ver 10,000 texts, it occurred to me that all these texts share the same common feature—they are teeming with dates. So, what if we try to identify such texts computationally?! Not only will this help us to find all relevant titles in the sea of text—without overlooking or missing anything!—we, arguably, can get an insight into the chronological coverage of each of those titles, the chronological focus of individual historians, the chronological coverage of the entire collection of historical texts, and identify texts that focus on particular periods. The blogpost begins with an overview of several digital collections and then explains the methodology of the experiment. Appendices offer one to explore the chronological coverage of about 1,000 individual texts as well as the coverage of particular periods (here, hijri centuries—i.e., which texts focus on particular periods).
Introduction
Digital collections of classical Arabic texts have mushroomed over the past decade and a half. The three major libraries—al-Ǧāmiʿ al-kabīr (HDD), Shamela.ws, ShiaOnlineLibrary.com—include over 10,000 titles. There is probably another dozen collections that offer texts in hundreds and thousands (for example, Alwaraq.net, Waqfeya.com, NoorLib.ir, GhBook.ir, Lib.Eshia.ir, Library.Tebyan.net, HathiTrust.org, Archive.org).
The number of these collections appears to be growing and their content expanding. This new research environment offers scholars an opportunity to check whether a particular text is included into in a certain collection, to browse and read it—often in a page-by-page manner—and to search for particular bits of information. These collections work well for looking for something that we know or expect to find—a book, a person, an event, a term. What we cannot do is to look into how books are related, how they overlap and complement each other; how each individual fits among his contemporaries as well as his predecessors and successors; how different historical events are intertwined; how terms, notions and concepts are related to each other and evolve across time and space. Yet, having full texts of our sources at our disposal, we can definitely go beyond simplistic linear searches. By asking a series of interconnected questions—and relying on digital methods of text analysis—we can move toward a new understanding of the entire Arabic written tradition (starting, of course, with what is digitally available in one form or another).
The question of chronology is one of such foundational questions. What I offer in this experiment is to explore the content of three such collections in order to understand better the chronological coverage of each collection, each author, and each book. In order to get insights into these issues we can turn to different kinds of data. To get a perspective on the scope of each collection we shall start with looking into descriptions of books and their authors. More specifically—into when authors died.
Metadata
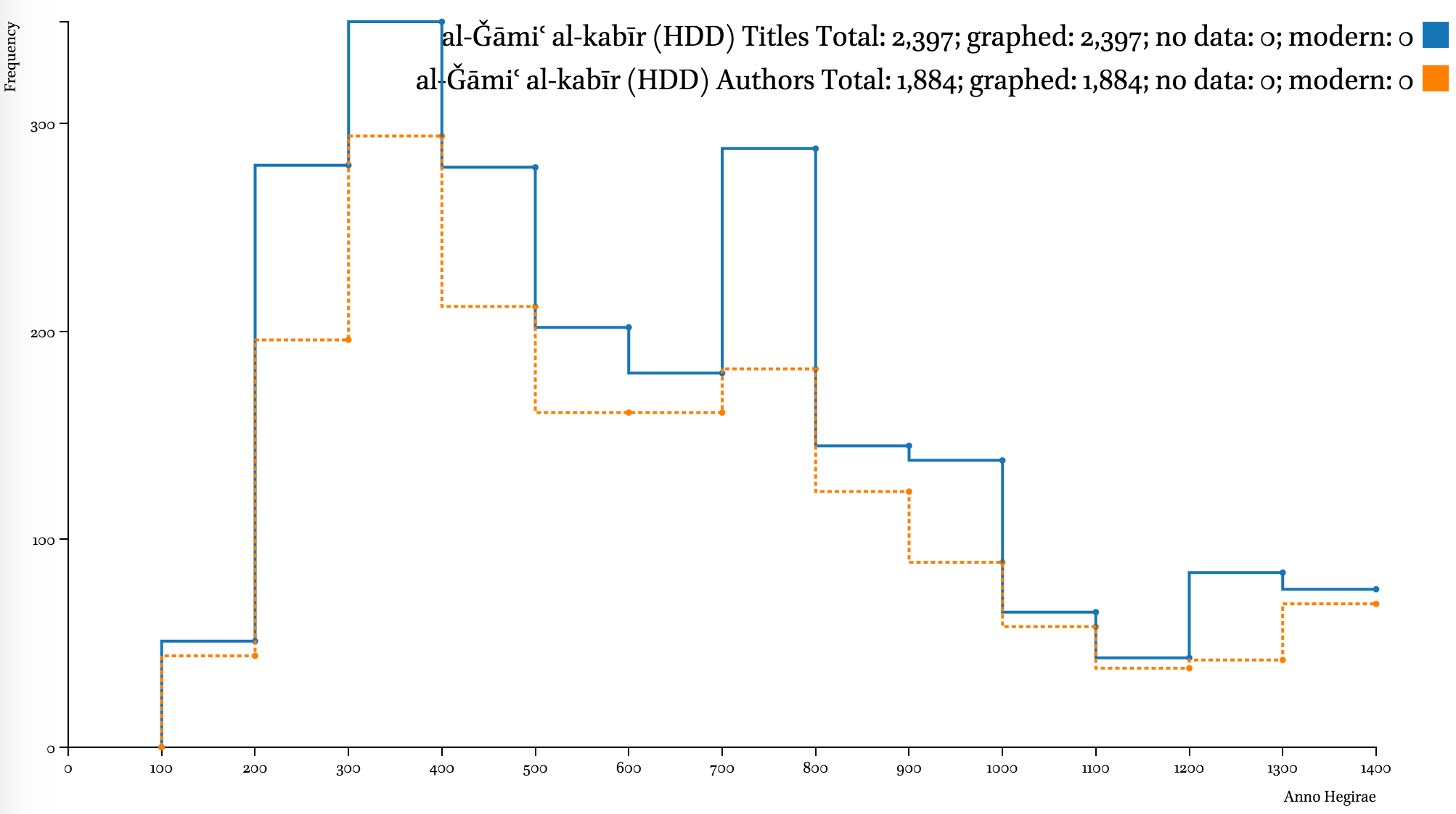
While metadata in most collections is not complete, it can still be quite useful. Major digital collections—al-Ǧāmiʿ al-kabīr (HDD), Shamela.ws, and ShiaOnlineLibrary.com—display the same clear trend: strong emphasis on the period from the 3rd–6th centuries AH (912–1203 CE), with an extra peak in the 8th century (1300–1397 CE), a steady decline during the 9th–12th centuries AH (1494–1785 CE), a slow recovery during the 13th century AH (1785–1882 CE), and skyrocketing in the 14th century AH (1882–1979 CE).
Note on graphs. Data points of each graphed line show frequencies for periods of time that end at that point. For example, on the graph below that shows distribution of data by 100 lunar years (titles in al-Ǧāmiʿ al-kabīr), the value for 300/912 CE is 280, which means that there are 280 titles written by authors who died during 200–300 AH / 815–912 CE. A “step-before” type of graph displays such data most appropriately, but it is not suitable for comparative graphs, since there is too much overlap among the lines which makes the entire graph unreadable. Data on the most recent authors (after 1400/1979 CE) is excluded from the graphs, since it tends to overshadow earlier periods.
{kind=link}
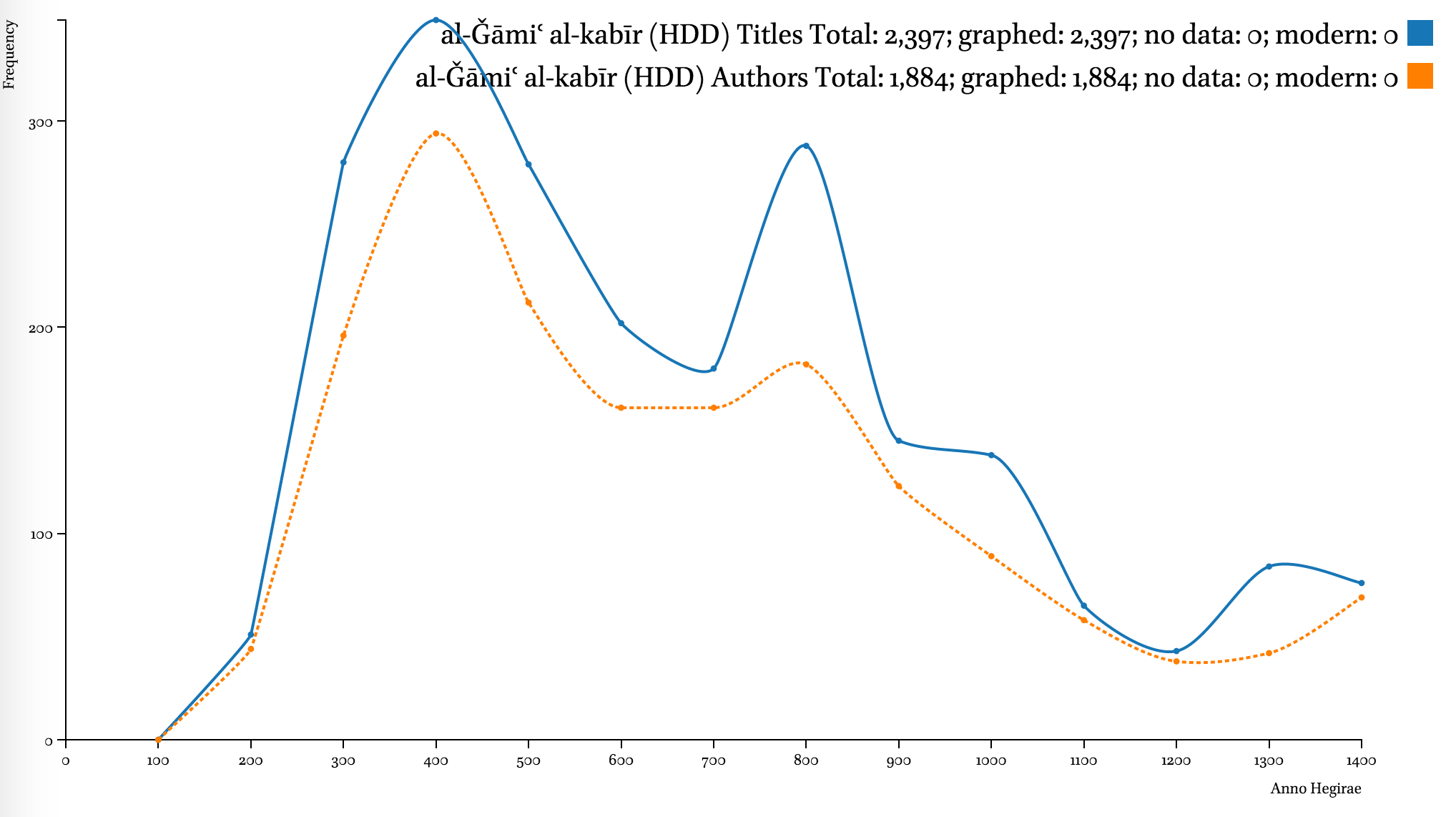
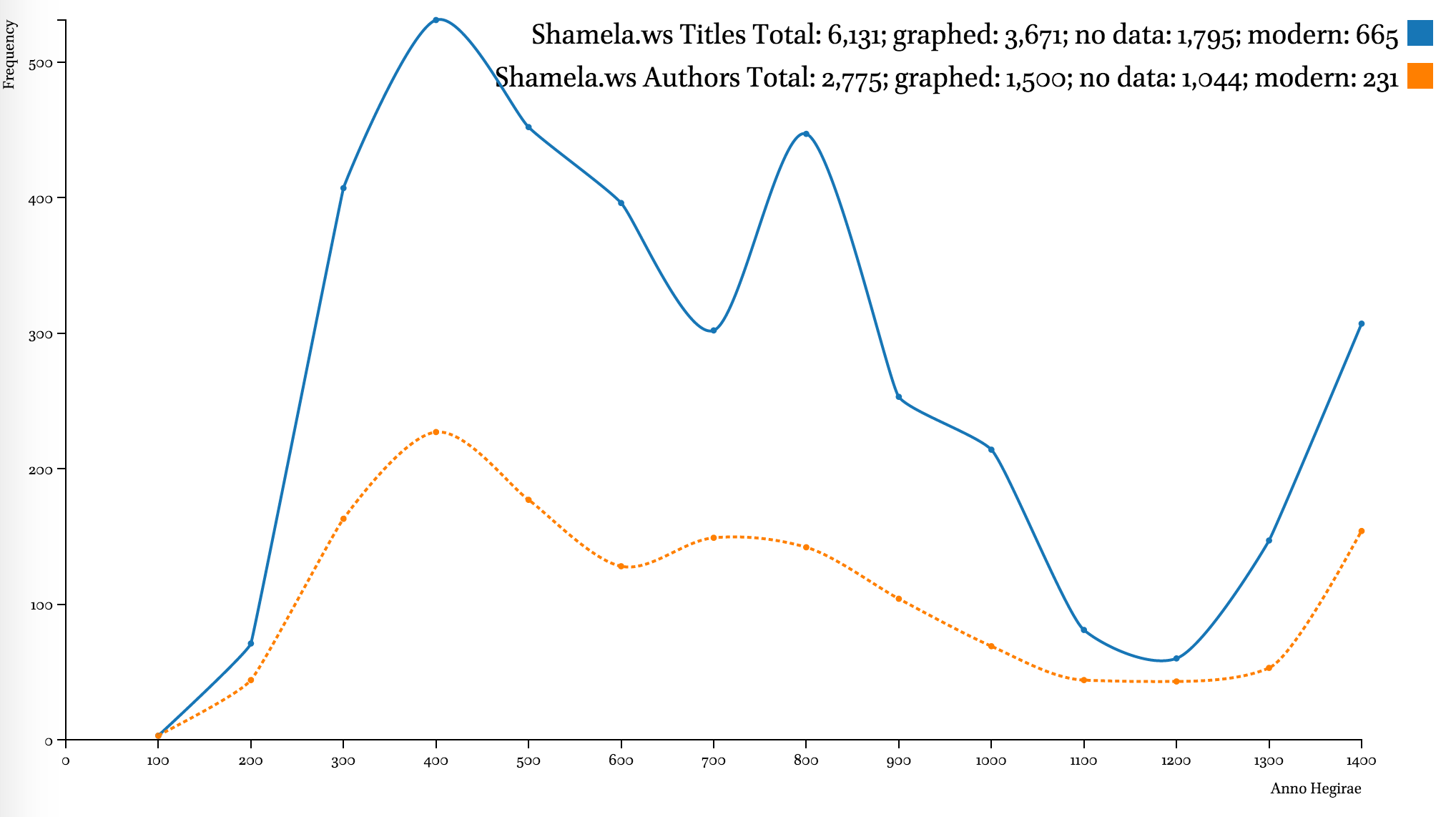
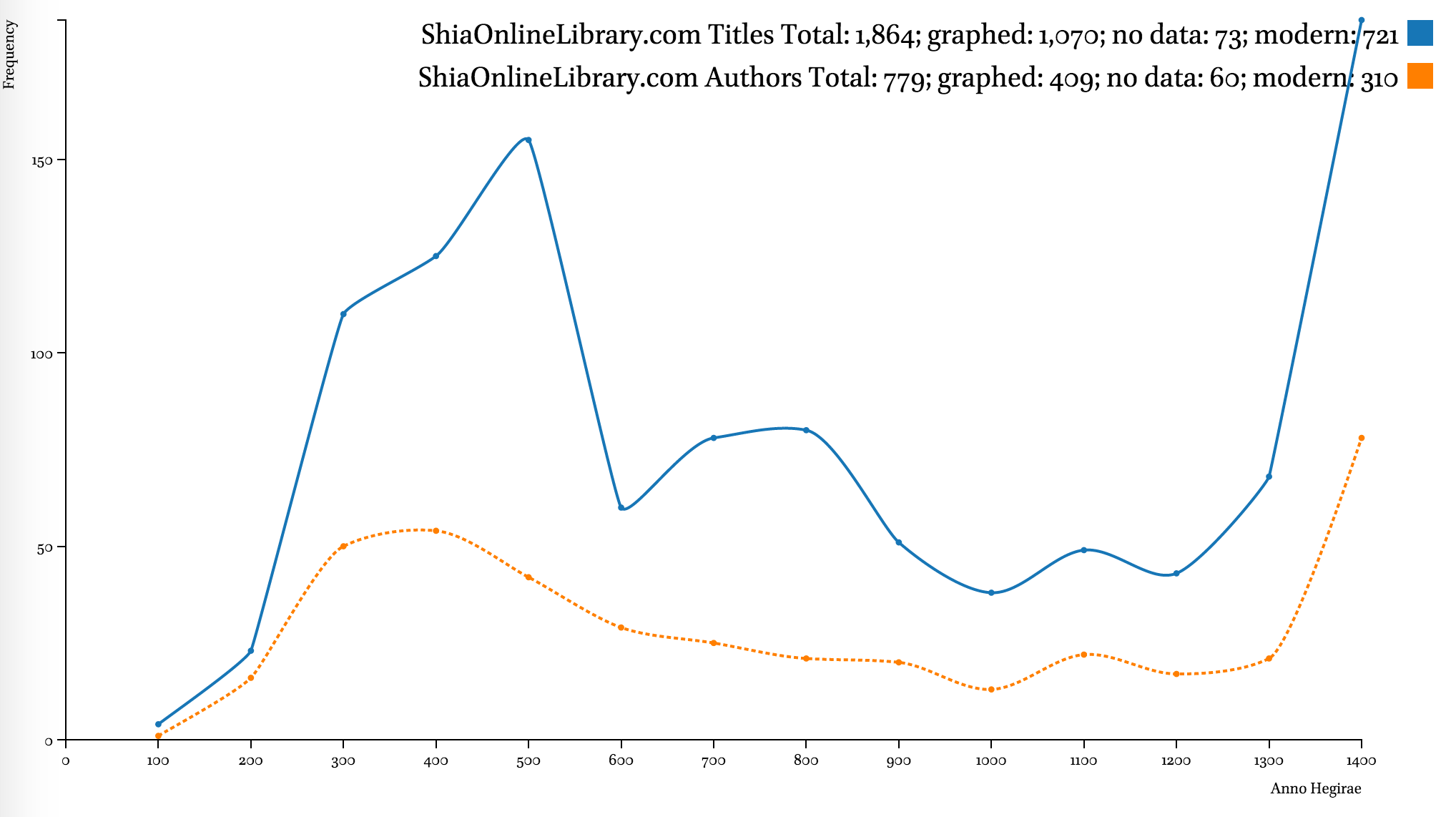
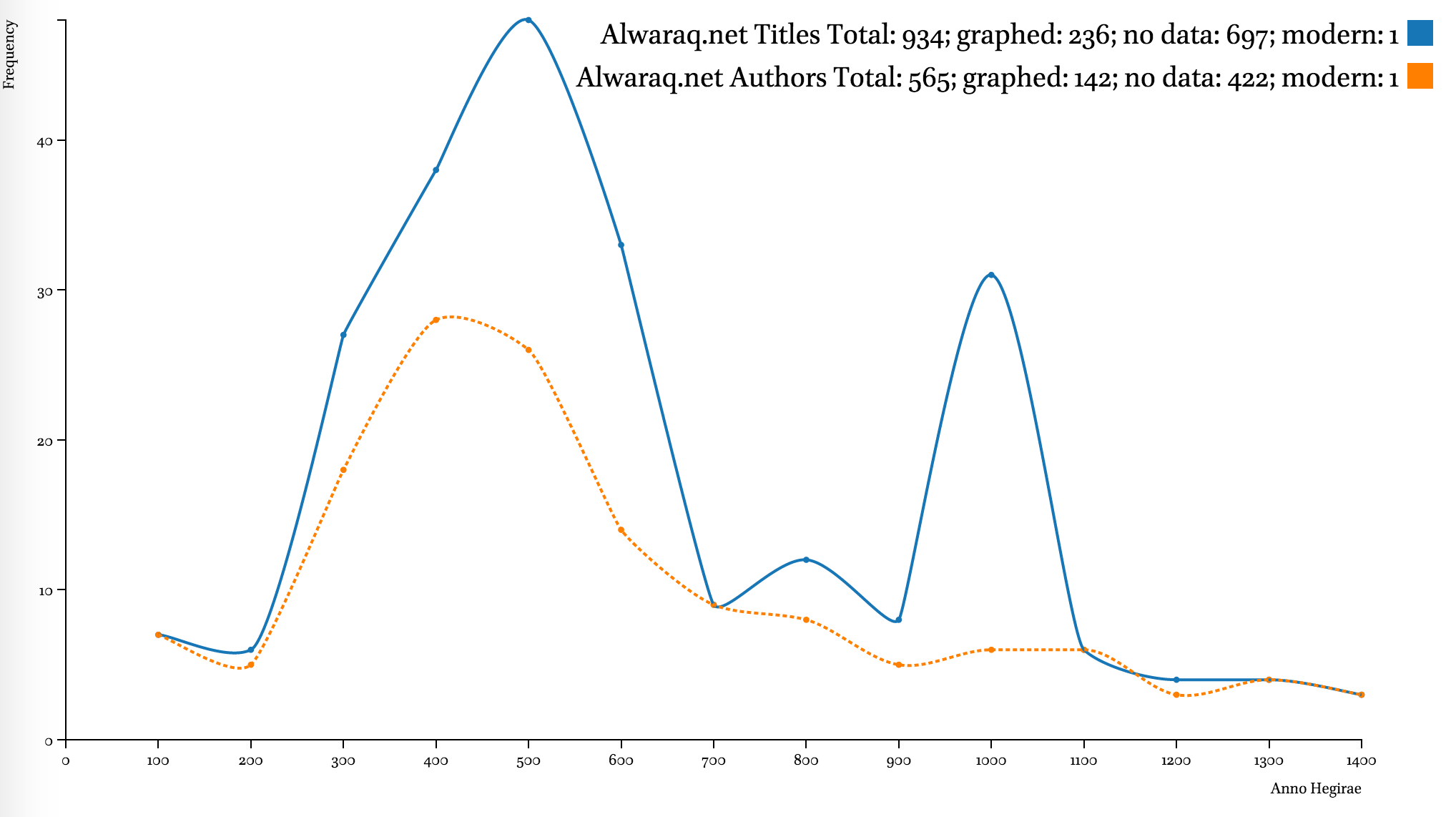
The developers of these collections were most interested in the early Islamic period (roughly the first half of the first Islamic millennium). According to the data of such sources as the Hadiyyaŧ al-ʿārifīn by Ismāʿīl Bāšā al-Baġdādī (d. 1338/1919 CE), a bibliographical collection that builds upon the famous Kašf al-ẓunūn of Ḥāǧī Ḫalīfaŧ (d. 1067/1656 CE), and Ḫizānaŧ al-turāṯ, a Saudi catalog of manuscripts (al-Riyāḍ: Šarikaŧ al-ʿArīs lil-Kumbiyūtir, 2007), the number of contributors to the Islamic written treasury is continuously growing at least up until the beginning of the 13th century AH.
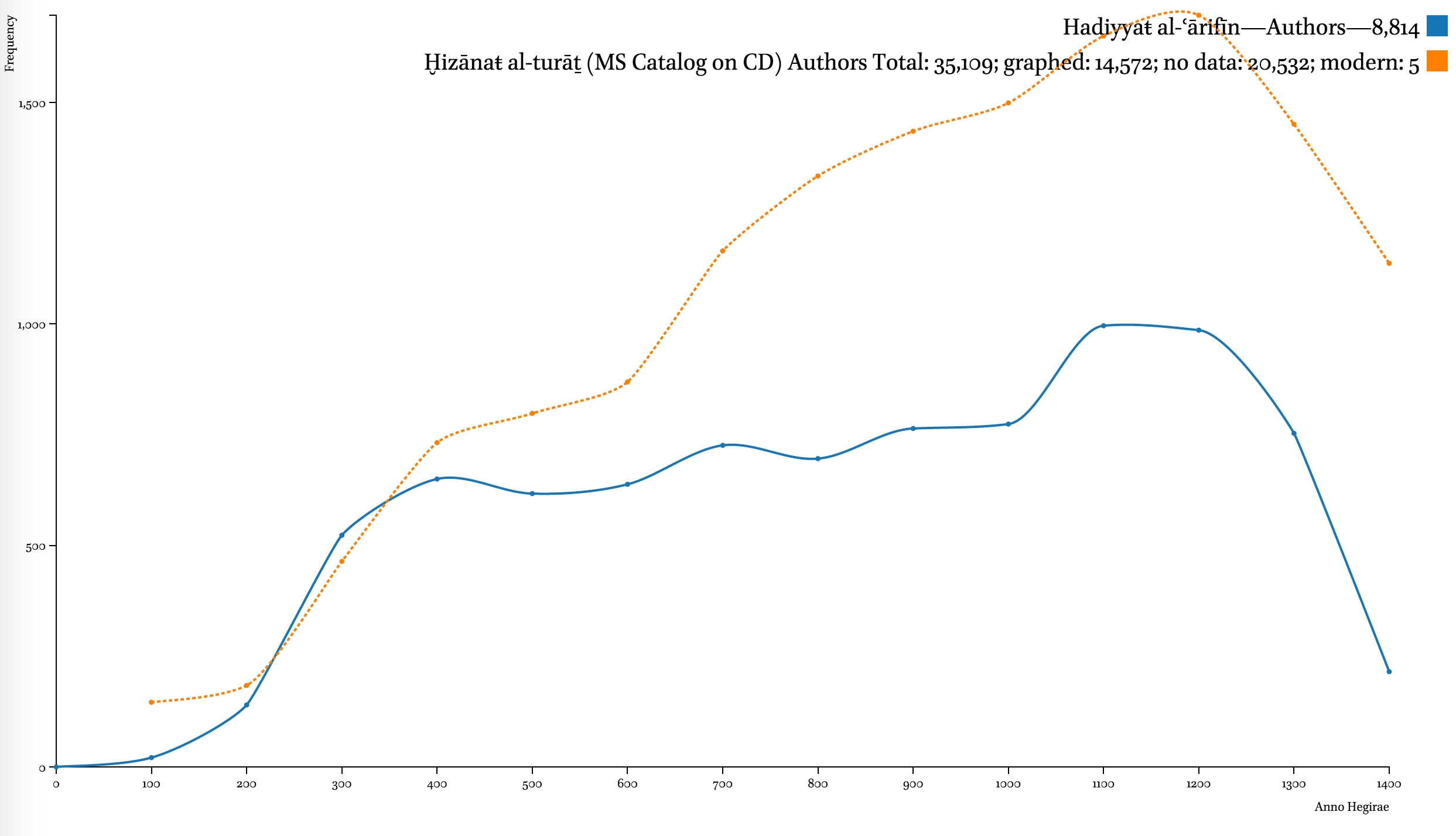
Ḫizānaŧ al-turāṯ is a Saudi catalog of manuscripts that was first published on a CD (al-Riyāḍ: Šarikaŧ al-ʿArīs lil-Kumbiyūtir, 2007); currently its full text is included into Shamela.ws. The catalog includes over 160,000 records, but unfortunately suffers from a number of problems, such as inconsistency of typing conventions, duplicate records, selective coverage of different manuscript collections (for example, only about 1,000 Arabic manuscripts from St.Petersburg, Russia are covered, while St.Petersburg academic institutions house at least 11,000 Arabic manuscripts).
Even though existing digital collections often awe us by their volume, the comparative graphs below shows that they cover only a fraction of the Arabic written tradition—even by comparison with an early 20th-century bibliography, which itself is hardly complete in its coverage. Additionally, the graphs also clearly highlights the fact that the chronological coverage of these collections is skewed heavily in favor of the earlier period of Islamic history.
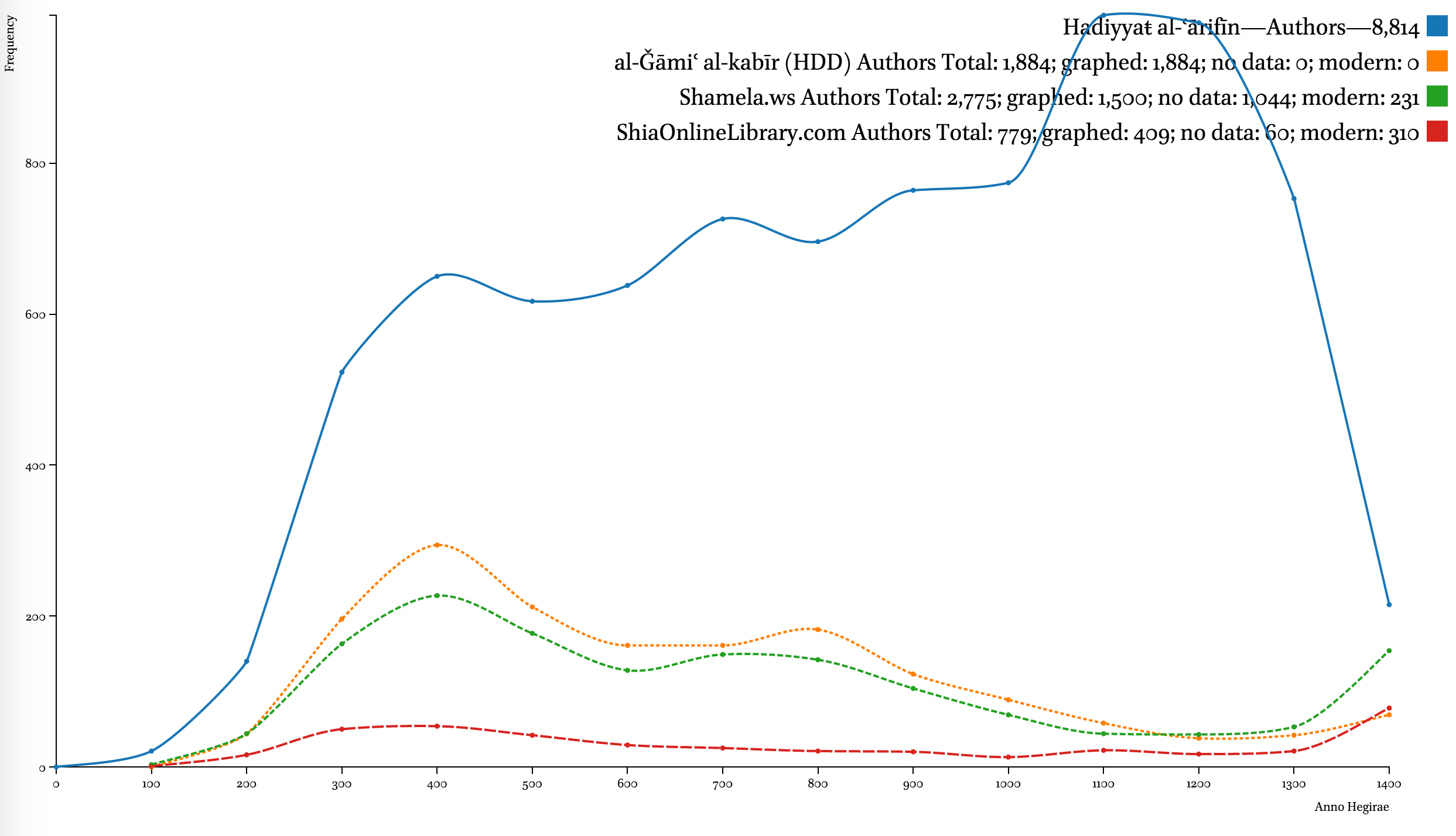
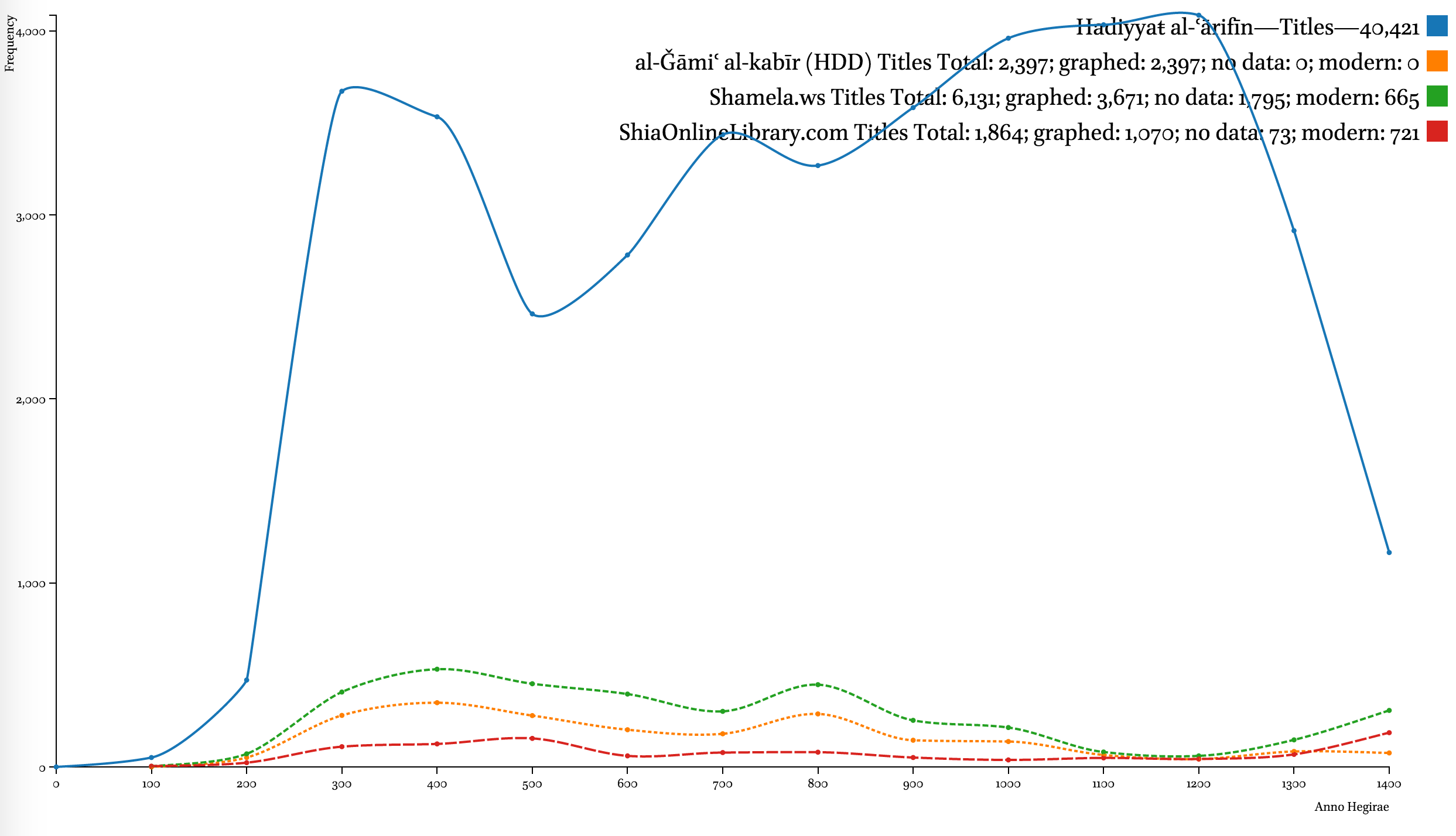
A note on the Hadiyyaŧ al-ʿārifīn. The decline of both graphs after 1200/1785 CE indicates unavailability of bibliographical information to the author more than anything else. The geographical coverage of the collection starts shrinking roughly at the same period. It should be noted that most chronological datasets exhibit a similar trend. For example, the trend can be observed in al-Ḏahabī’s own Ḏayl to his Taʾrīḫ al-islām, where the number of biographies drops dramatically; one can equally see the same trend in Brill’s Index Islamicus and Harvard Open Metadata (on 12 million books). The only difference is that the lag gets shorter as we get closer to our time—for premodern Arabic sources this lag is 100 to 150 years; in modern datasets—10 to 20 years.
Another way to evaluate chronological coverage is too explore the actual texts. Ideally, the number of discrete units of information—such as, for example, biographies and events—by periods should show the distribution of chronological emphasis of a particular source. Furthermore, the summary of such data from all [available] titles written by a specific author should indicate this author’s interest in specific periods. (The interpretation of such “interest” is a different subject altogether. For example, the fact that the Hadiyyaŧ al-ʿārifīn has more information on the 11th and the 12th centuries AH (1591–1785 CE), may indicate either Ismāʿīl Bāšā al-Baġdādī’s interest in this particular period, or the availability of information for this period, or the genuine growth in numbers of people contributing to the Islamic written treasury.)
Date Statements
Almost none of the texts, however, are tagged in a manner that would allow to do such a detailed evaluation. Yet, it is possible to analyze date statements in each texts and offer an evaluation of their chronological coverage based on the frequencies of references to different periods. The consistency of date statements in Arabic texts—essentially, a word for “year” (ʿām or sanaŧ) followed by either digits or spelled-out numbers—makes it possible to represent this pattern with a regular expression, a special text string for describing a search pattern (see Figure below). This regular expression can be worked into a script, with which one can check available texts. It should be noted, of course, that this approach is tuned to analyze hiǧrī dates, since other dating systems are used only infrequently.
Words sanaŧ and ʿām in the histories of Islam. Overall, the word sanaŧ is used most frequently in date statements: of about 1,362,000 date statements from across 10,000 texts only 2.9% of statements start with the word ʿām (~40,000), while 97.1% begin with the word sanaŧ (~1,322,000). Closer look also reveals that the word ʿām is favored in texts written in the 20th century; with regards to premodern texts, it can be said that authors from the western part of the Islamic world—al-Andalus and al-Maġrib—tend to use it more frequently, than their eastern counterparts.
Note: Adding fī “in,” into the mix changes the picture into: of about 1,670,000 statements, 79.2% start with sanaŧ (~1,322,000), 18.5% with fī (~308,000), and 2.4% with ʿām (~40,000). The problem is that even a quick look at the ngrams of fī-statements—the words that immediately follow each fī-statement—shows that more than a half of these statements are quantitative phrase of different kind (for example, fī arbaʿ mujalladāt). For this reason, fī-statements are excluded from the analysis.

Such an approach is not without its problems, of course, but it may serve well as an exploratory technique. The results of the experiment are intriguing in a number of ways, even though not entirely consistent. The most important outcome is that it allowed to discover that the collection of 10,000 texts contains only about 785 texts with more than 100 date statements per text (and since the included collections overlap, the number of unique titles is even smaller). Needless to say, that working with 785 texts is significantly easier than working with 10,000 titles. Additionally, frequencies of date statements for each text offer an opportunity to focus one’s efforts on texts that contain most data suitable for time-series analysis.
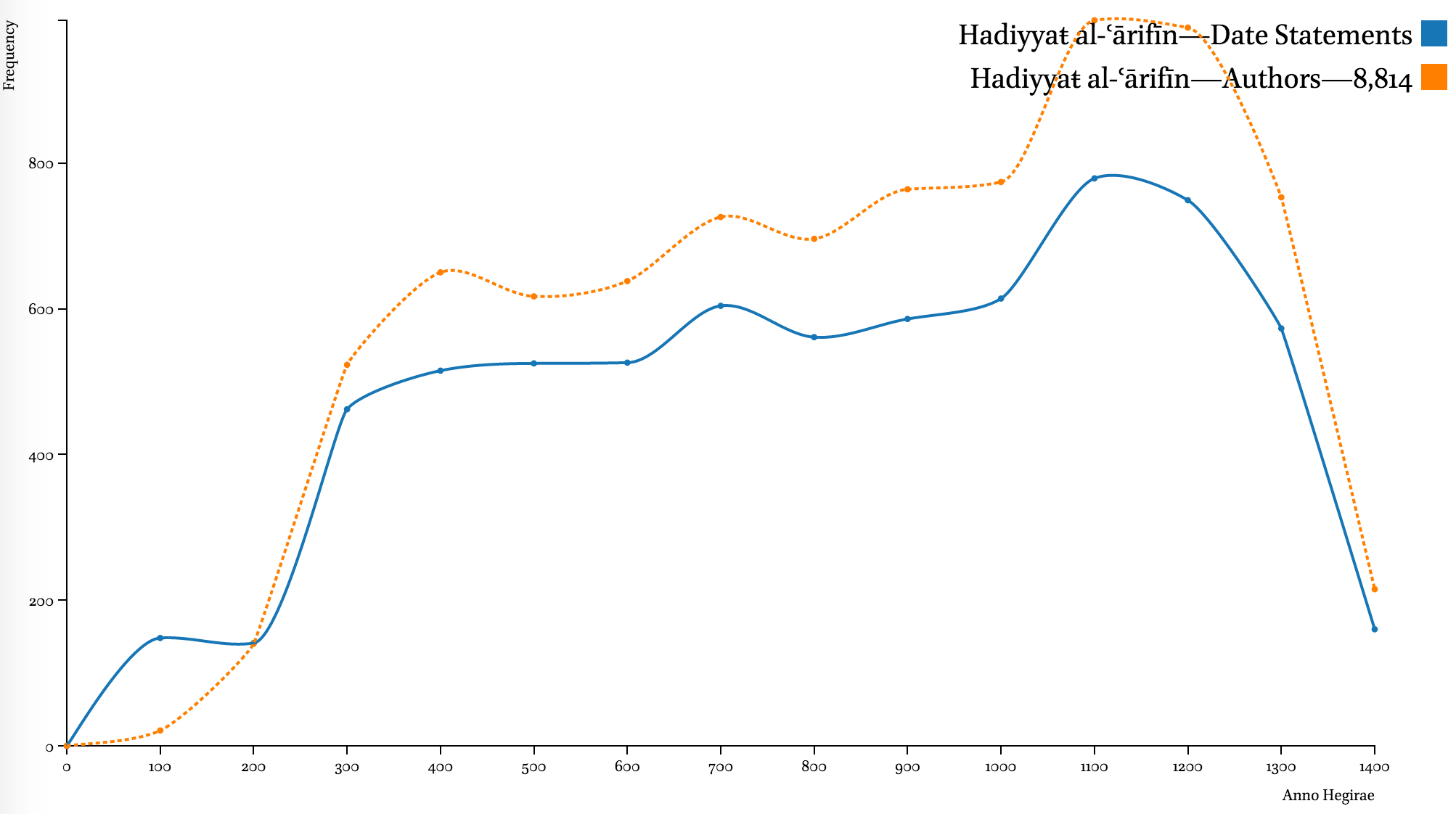
The graph above shows two different representations of the chronological coverage of the Hadiyyaŧ al-ʿārifīn by Ismāʿīl Bāšā al-Baġdādī (d. 1338/1919 CE), a bibliographical collection that builds upon the famous Kašf al-ẓunūn of Ḥāǧī Ḫalīfaŧ (d. 1067/1656 CE). The blue line shows the frequencies of date statements by periods (binned into 50 year periods)—strongly suggesting more emphasis on the 11th an 12th centuries AH (1591–1785 CE). The orange dotted line shows the distribution of biobibliographical records on about 8,800 authors—this actual distribution of discrete information units in the source emphasizes the same period of the 11th and 12th centuries. The similarity in the patterns of distribution shows that reliance on computationally extracted date statements is a viable alternative.
The 1st Century Problem
Unfortunately, many texts suffer from what can be characterized as “the 1st century problem”: authors often drop hundreds from date statements (authors from the second millennium also tend to drop thousands), which leads to a very high number of date statements referring—at the face value—to the 1 st century AH (622–718 CE). As a result, the 1st century often gets inflated, overshadowing other periods. The graph below illustrates this issue.
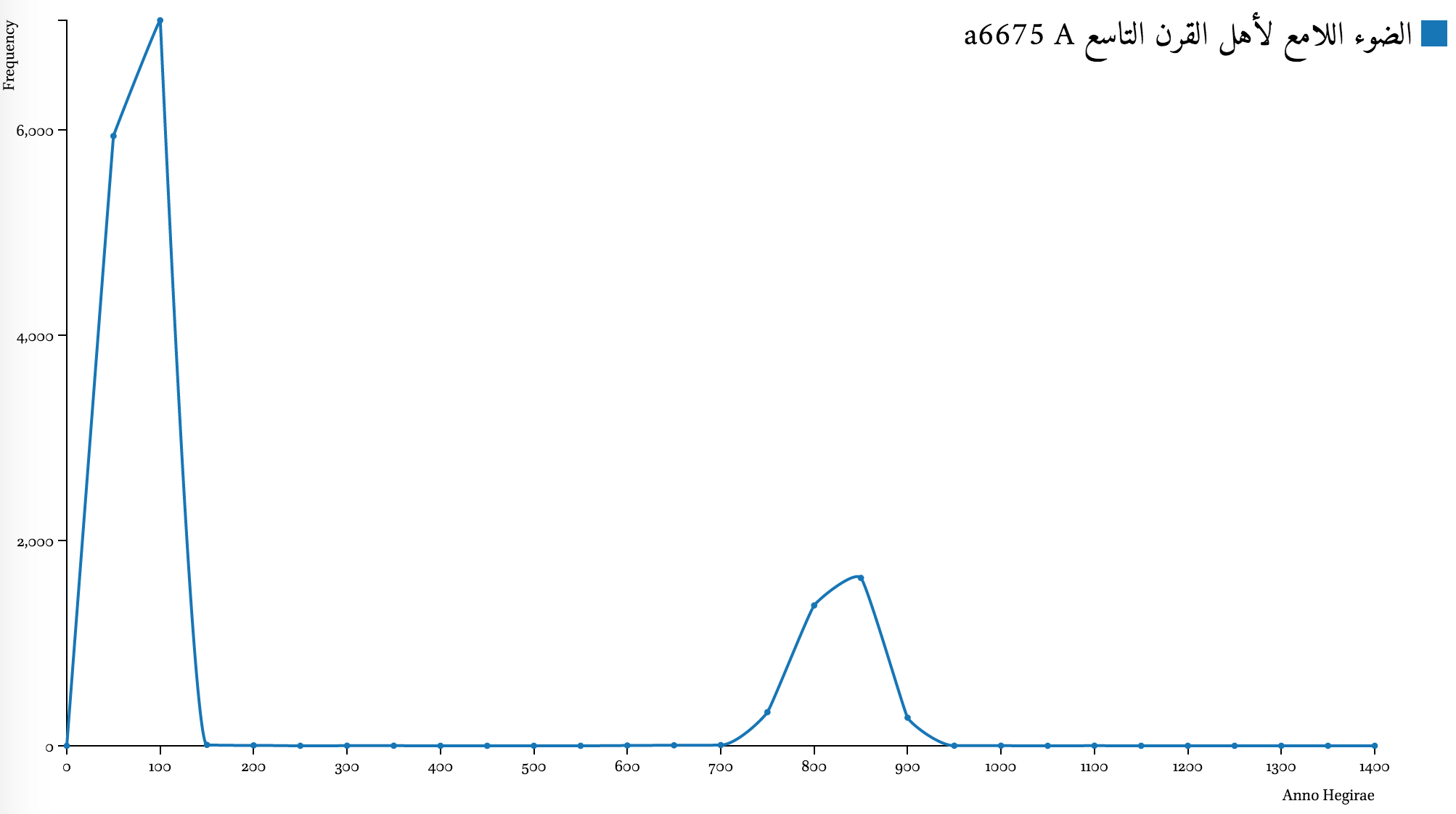
The problem may be resolved through the sequential analysis of date statements in texts. Authors are not likely to drop hundreds from their statements without letting their readers know what century they are talking about. In other words, an incomplete date statement must be preceded by a complete one. Thus, one can check if there are other date statements—and if there is, the incomplete date can be fit into the period of the preceding statement.
The actual implemented algorithm grabs a 100-word chunk before a 1st-century date statement and checks if there are other date statements in that chunk. The procedure is repeated up to five times, that is checking up to 500 words—an equivalent of 1 to 3 printed pages—before the date statement in question, until either the text limit is reached or a date statement found. If a date statement is found, its century gets applied to the starting date statement that we treated as incomplete. In other words, if we start with “the year 65”, and we find “the year 530” preceding it, we change the first date into “the year 565” (1169 CE). If the preceding date is also from the 1st century, the starting date remains unchanged; the date also remains unchanged, if no other date statements have been found. Additionally, the algorithm runs in two different ways—in the first case, it does not build on updated date statements (Lines B); while in the second, it does, extrapolating from corrected date statements (Line C). The graph below shows the results.
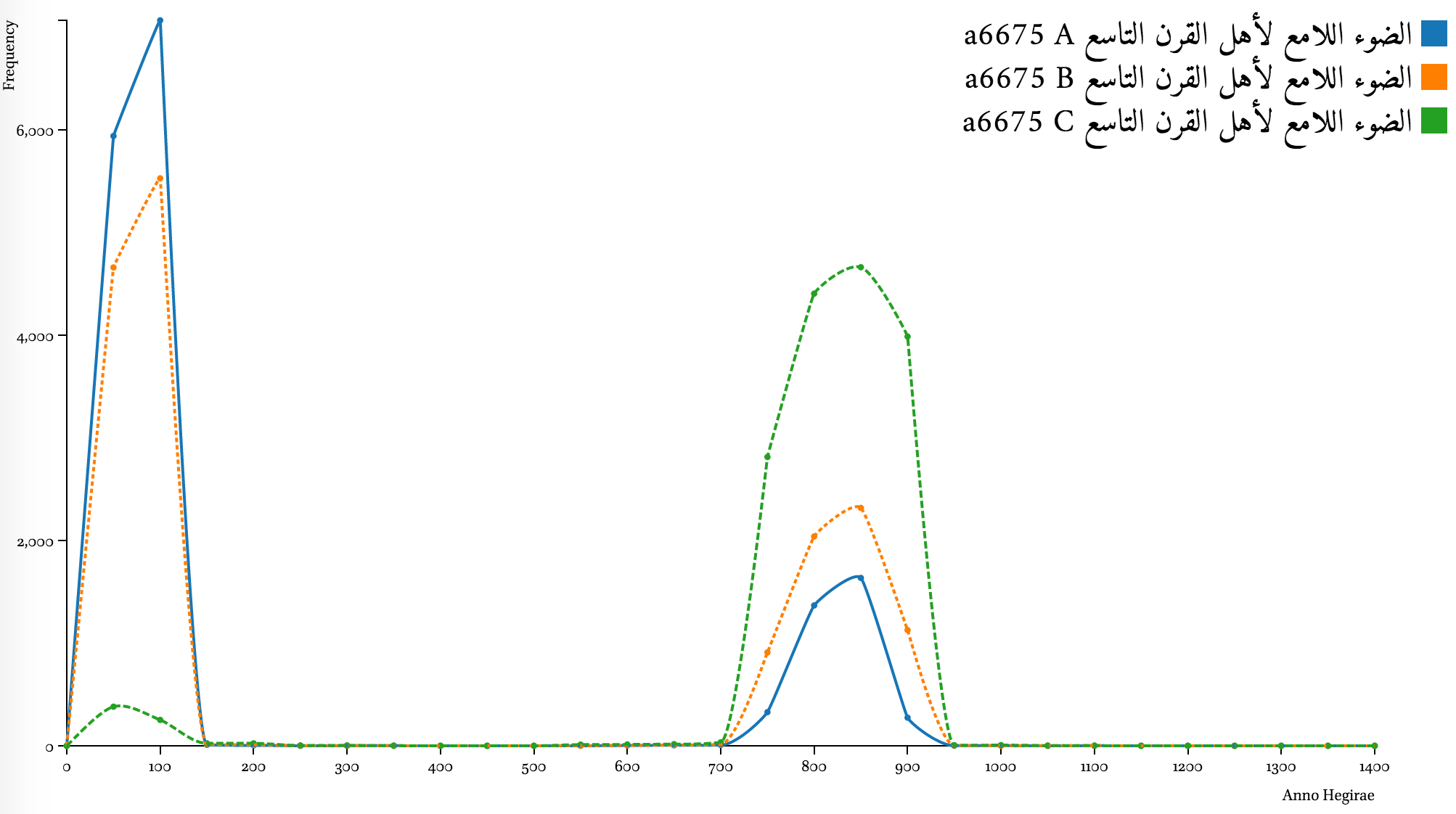
Note: a6675 is the identifier of a particular version of the text—title #6675 from al-Maktabaŧ al-Šāmilaŧ; the same title from a different collection will have a different identifier.
The question is, of course, how reliable such projections are. In order to check this we need to compare algorithmically produced results with manually disambiguated data. The graphs below show such comparisons for four different sources: A (orange dotted) shows the initial results of computational date statements collection; B (green dashed)—modified dates without extrapolation; C (red dashed)—modified results with extrapolation; and, finally, D (blue solid)—shows manually disambiguated 1st-century date statements.
al-Wafayāt al-aʿyān of Ibn Ḫallikān (d. 681/1282 CE)
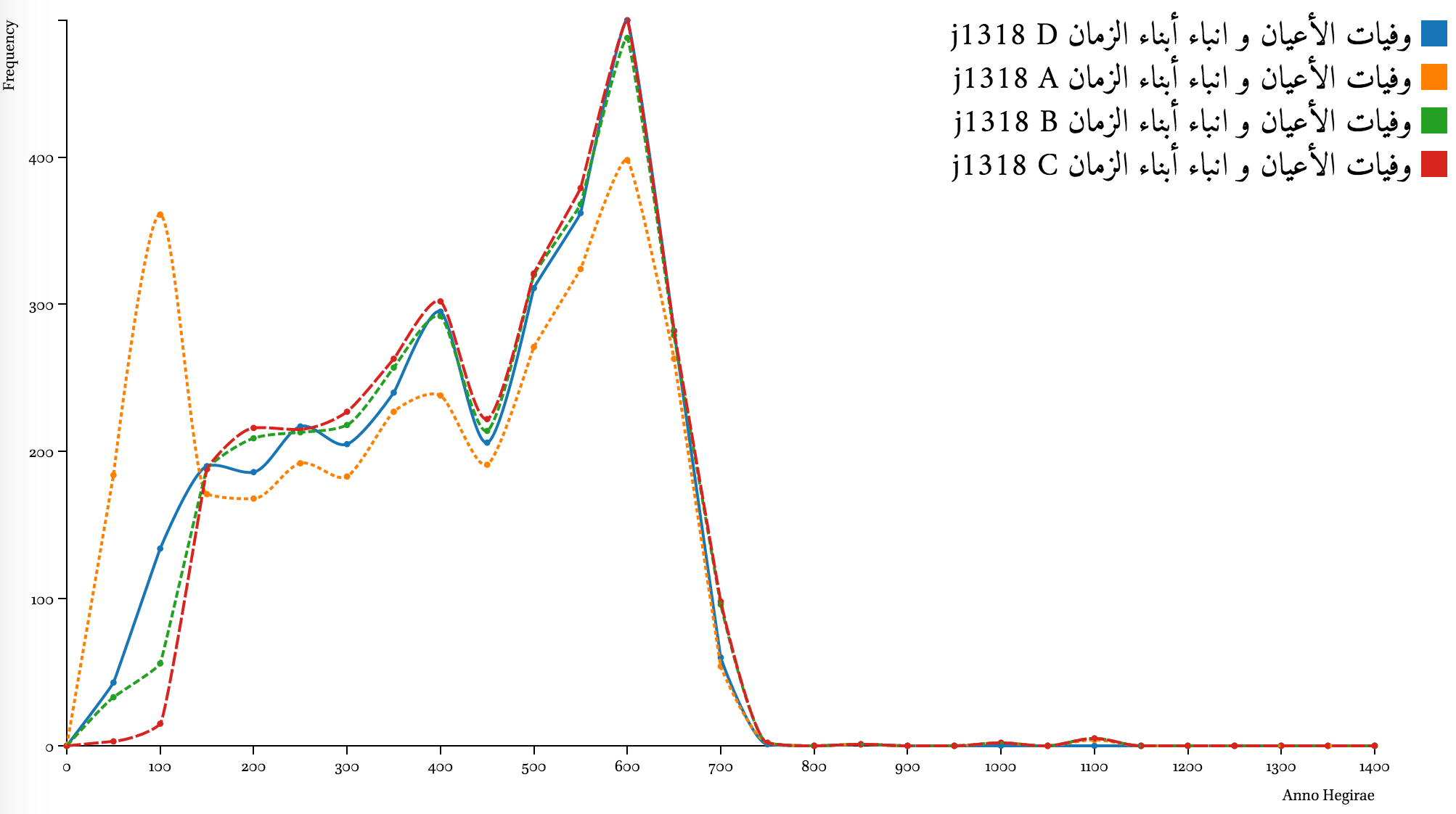
Results for Ibn Ḫallikān’s al-Wafayāt al-aʿyān are very good—algorithmically modified dates are very close to manually disambiguated. Results of Algorithm B—modified results without extrapolation—are slightly closer to the benchmark (line D) than the results of Algorithm C. Yet, both are somewhat “overfitting” 1st-century dates. Good news: algorithmic lines B and C lead to the same conclusion as the benchmark Line D—Ibn Ḫallikān covers the period of 450–650 AH / 1058–1252 CE most thoroughly.
al-Kāmil fī-l-taʾrīḫ of Ibn Aṯīr (d. 630/1232 CE)
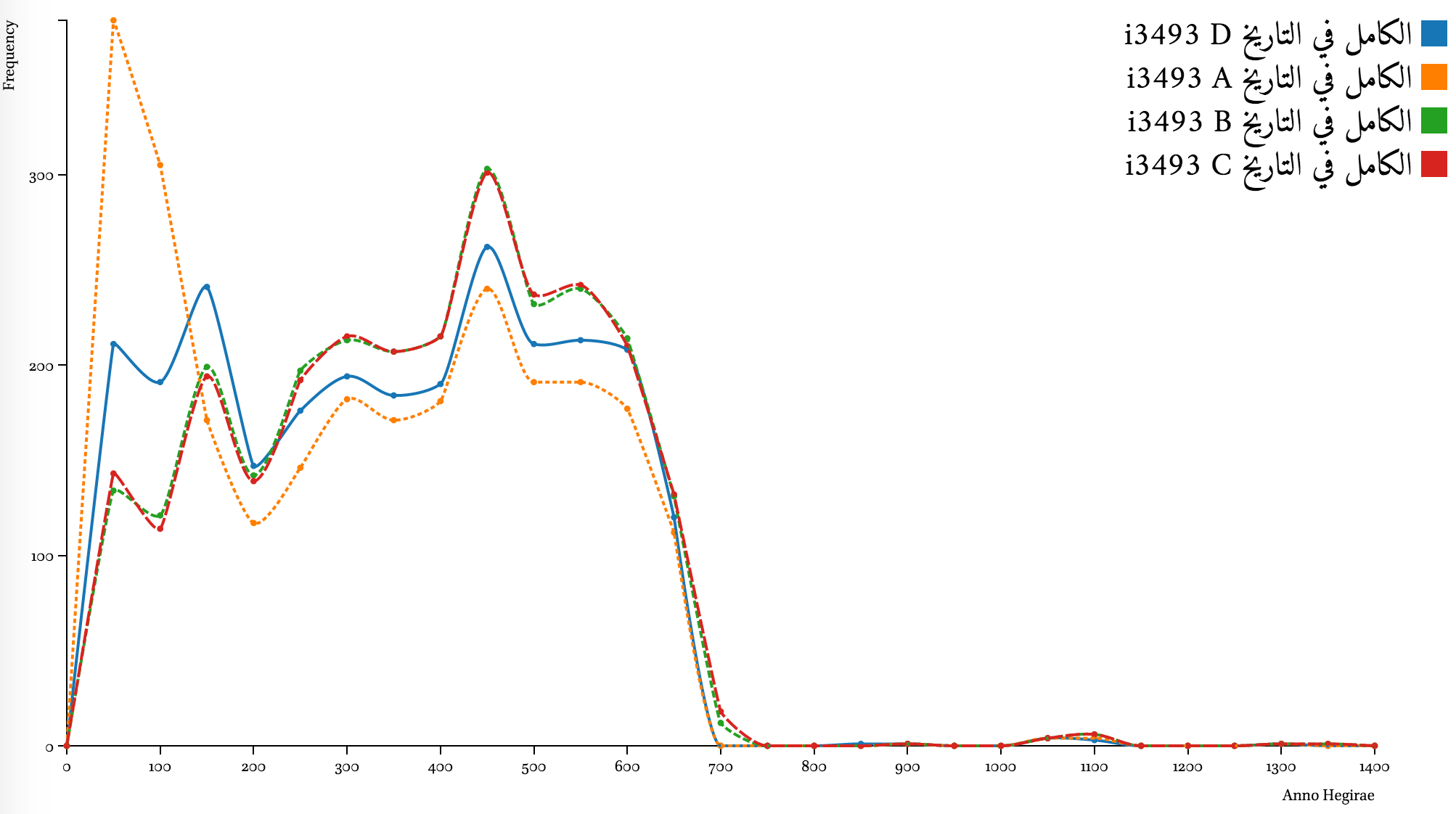
Results for Ibn Aṯīr’s al-Kāmil fī-l-taʾrīḫ are less precise: both algorithms overfitted 1st-century dates, inflating other centuries, if compared to manually disambiguated data (D). The peaks of distribution—the shape of the curve—are much closer to the benchmark than the preprocessed results (A), but computational analysis suggests that Ibn Aṯīr focuses more on the later period, while (according to manually disambiguated data) his attention is spread more evenly.
Ṭabaḳāt al-šāfiʿiyyaŧ of Ibn Ḳāḍī Šuhbaŧ (d. 851/1447 CE)
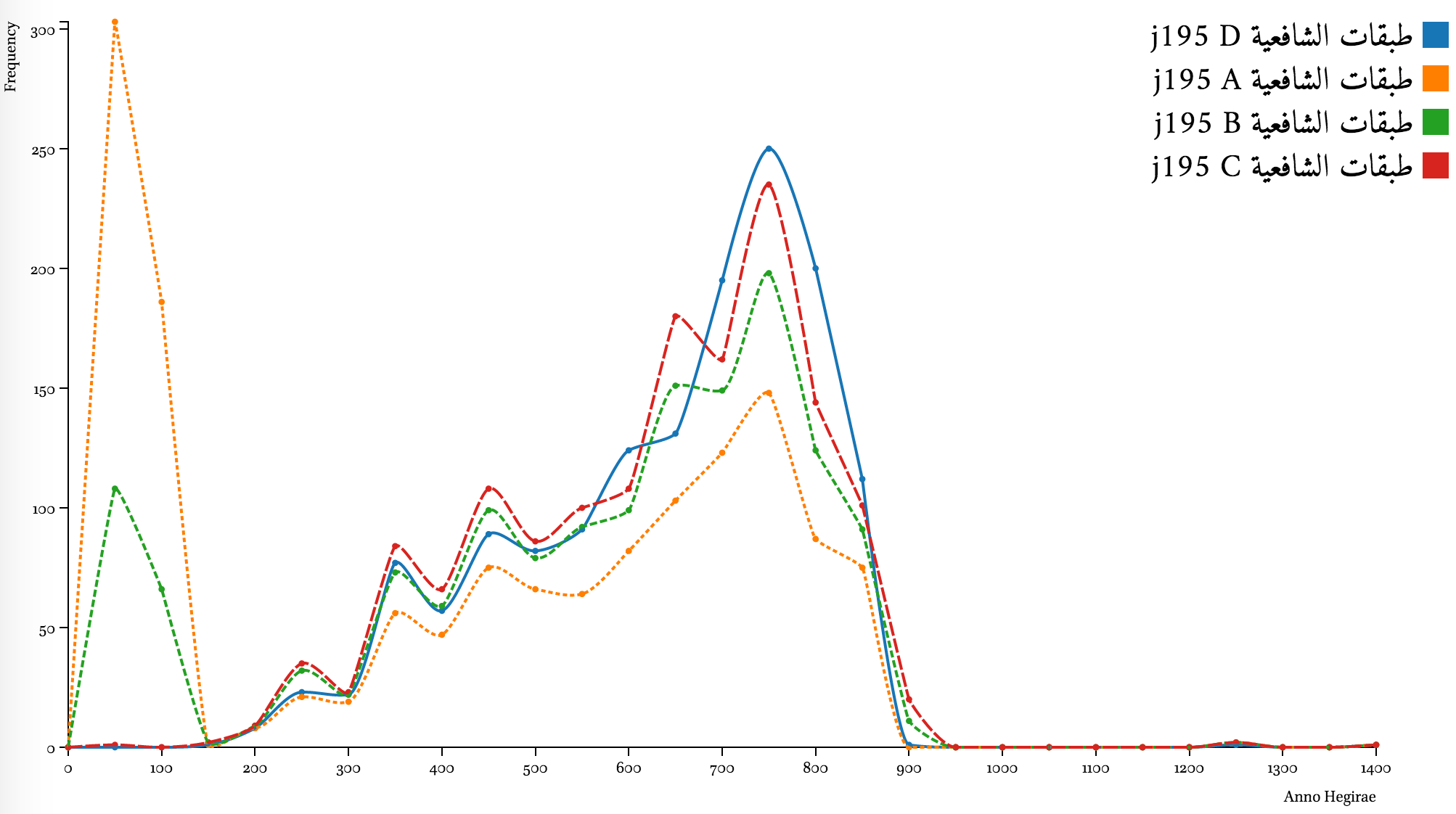
Results for the Ṭabaḳāt al-šāfiʿiyyaŧ of Ibn Ḳāḍī Šuhbaŧ are not ideal, but still much better than the initial results. Extending the check range from 500 words to 1,000 gets the graph—line C in particular—much closer to the benchmark (click on the image to see the graph based on the extended range of 1,000 words). The problem, however, is that for other sources 1,000-word range does not generate better results.
Some general observations
We are clearly not getting 100% match with the benchmark, but that is not to be expected anyway—none of the exploratory computational methods work that way. Our model does not take into account the stylistic differences among authors. While the ballpark of date statements do fall into the proposed pattern there are occasionally slight variations that are peculiar to particular authors. Some of such peculiarities may be helpful. For example, Ibn Ḫallikān often uses phrases li-l-hiǧraŧ or min al-hiǧraŧ with the true 1st-century date statements (which is still 75-80%)—and such markers can be worked into the algorithm; other authors—about half a dozen that I checked thoroughly—use such additional phares only occasionally. Other peculiarities are too complicated and cannot be resolved with simple algorithms. For example, Ibn Ḳāḍī Šuhbaŧ occasionally “spells” out ones in his date statements to ensure that his readers get it right: sanaŧ sabʿ bi-taḳdīm al-sīn wa-ʿišrīn …, “the year seven, with sīn in the beginning…”), which, again, breaks the general pattern for date statements. The most complicated issue, however, is that even for a scholar it may occasionally be difficult to figure what century a certain date refers to (for example, when a biographee was born close to the middle of one century and died close to the middle of the next one). Natural languages will always pose such difficulties, yet, the results produced with the offered approach are quite suitable for the goal: even when we do not get the exact results, we are still getting close enough to the benchmark for a useful distant reading of a large corpus.
The precision of results also varies because of differencies in book structure. We get more precise projections for books organized alphabetically—in this case authors cannot afford to use too many incomplete dates (see graphs for the Hadiyyaŧ al-ʿārifīn and Wafayāt al-aʿyān above); and less precise for books organized chronologically. It would make sense to develop different subroutines for processing texts based on their organization. Having robust metadata on each text would help triggering analytical routines adjusted to various peculiarities, although the structure of a book can be inferred computationally (on this see below). Additionally, a more precise logic can be implemented if our texts are properly divided into logical units. Thus, in a book organized alphabetically, the analysis of dates would be limited to a single logical unit, while in a book organized chronologically the precision of analysis can be inforced by looking into date statements in the neighboring units. At this point, results are provocatively suggestive—but in most cases some familiarity with a specific book will help make sense of its graphs.
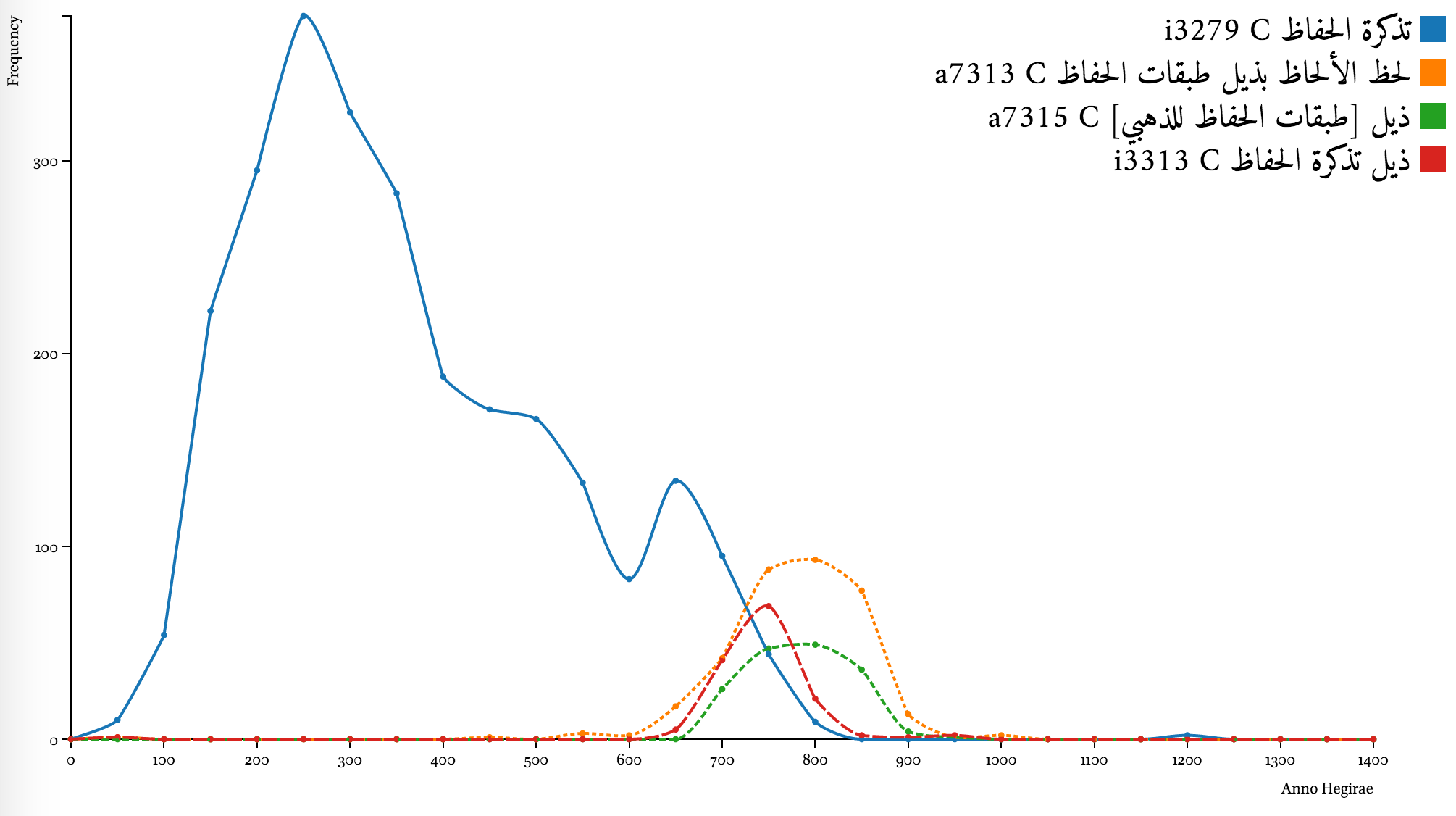
Complementary coverage of “continuations”
Date statements may also offer other useful insights into Arabic historical sources. Comparing chronological coverage of different texts may offer an illustration of how text related to each other. Graphs below show a few examples of how certain texts are overlapping chronologically with their “continuations” (ḏayl, takmilaŧ, ṣilaŧ) and are complemented by them.
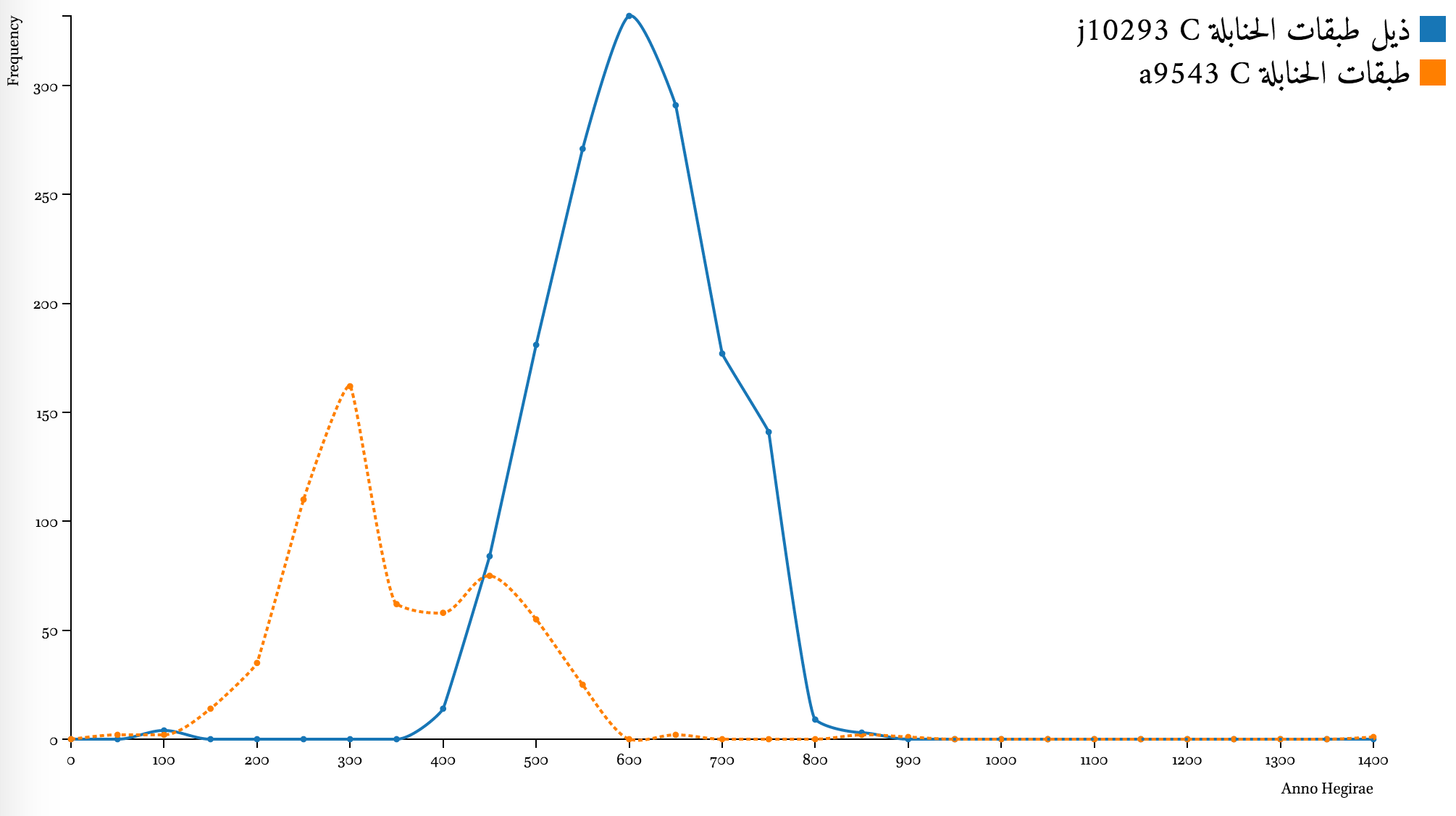
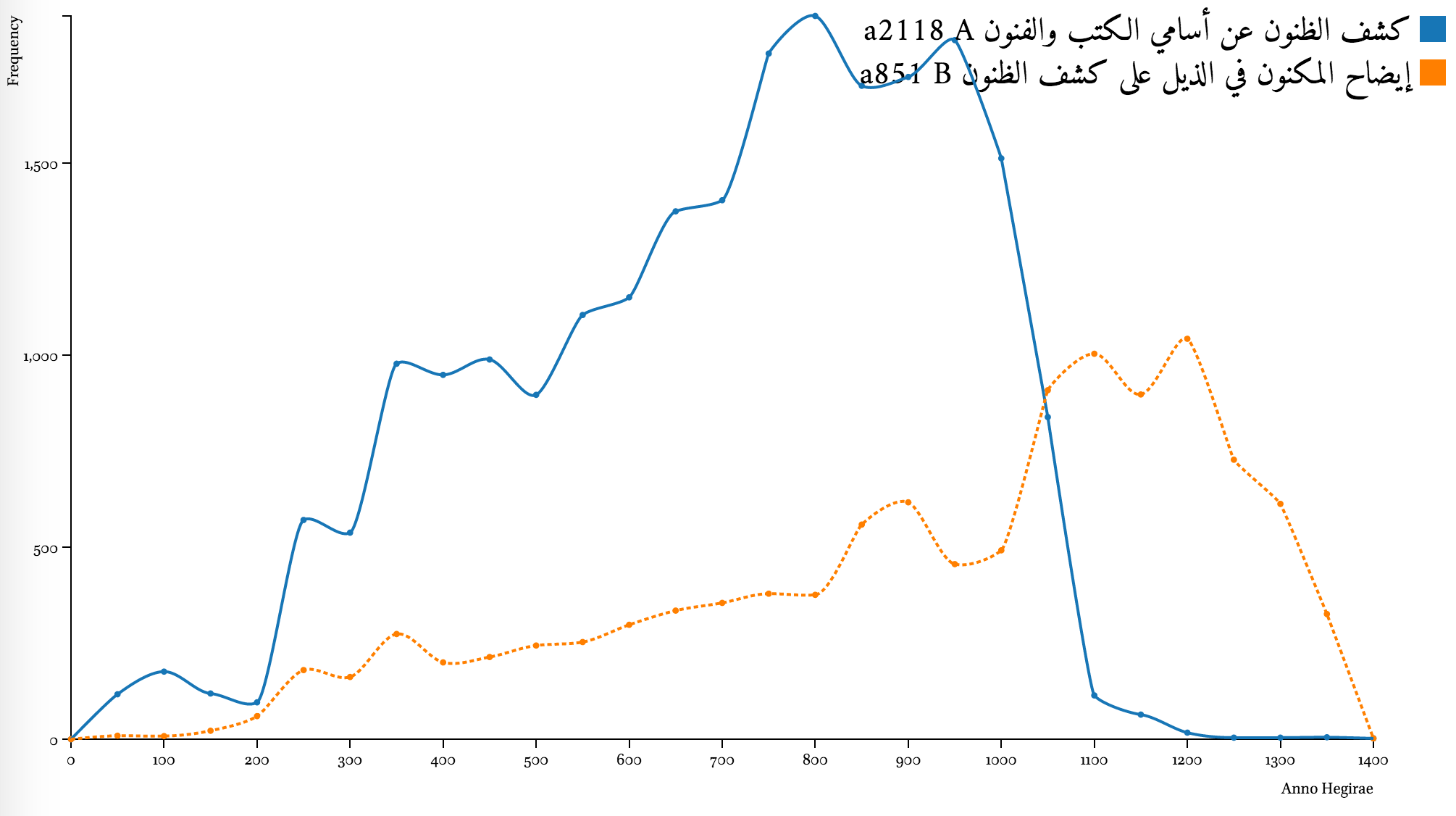

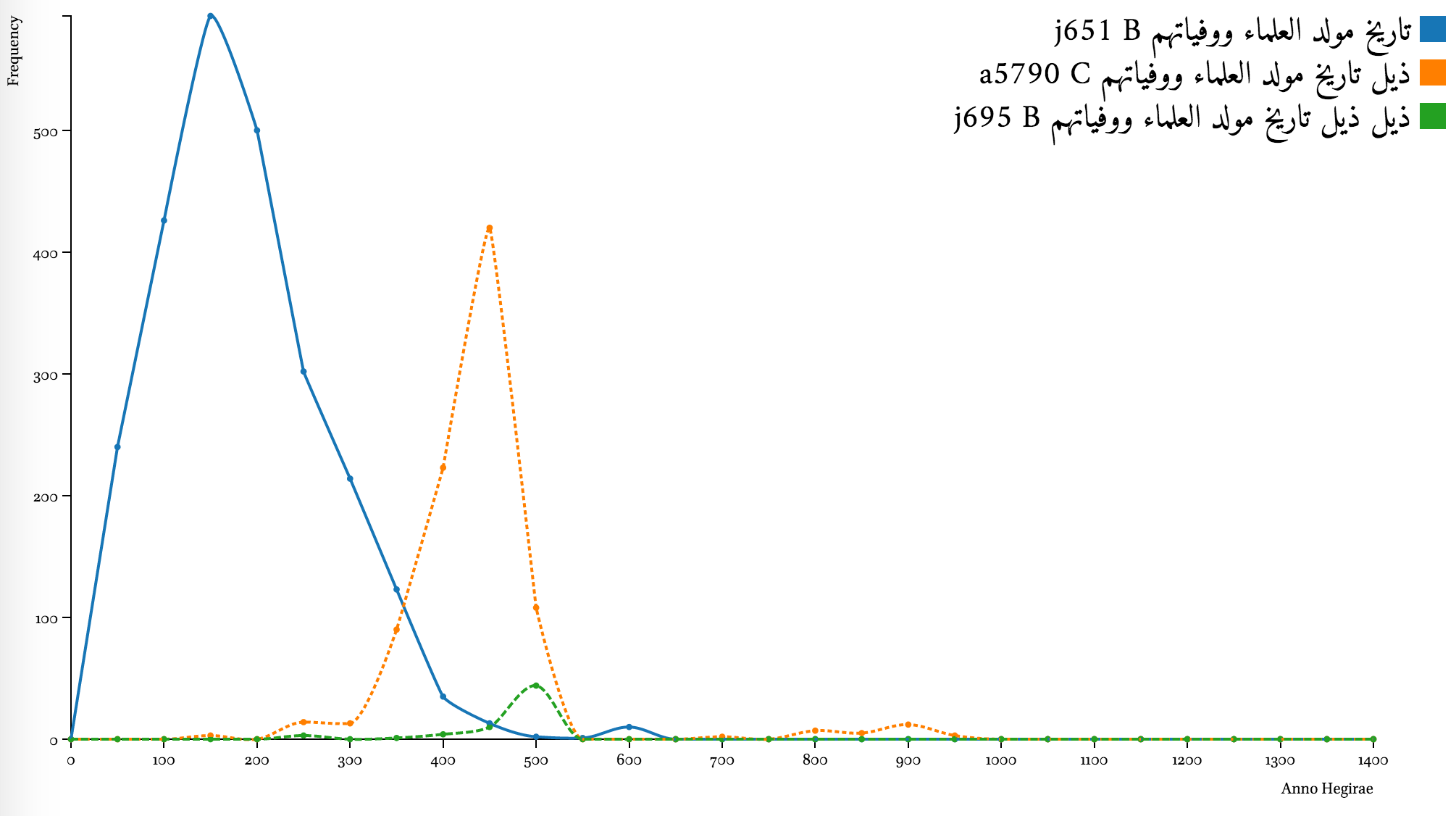
Date statements and the structure of books
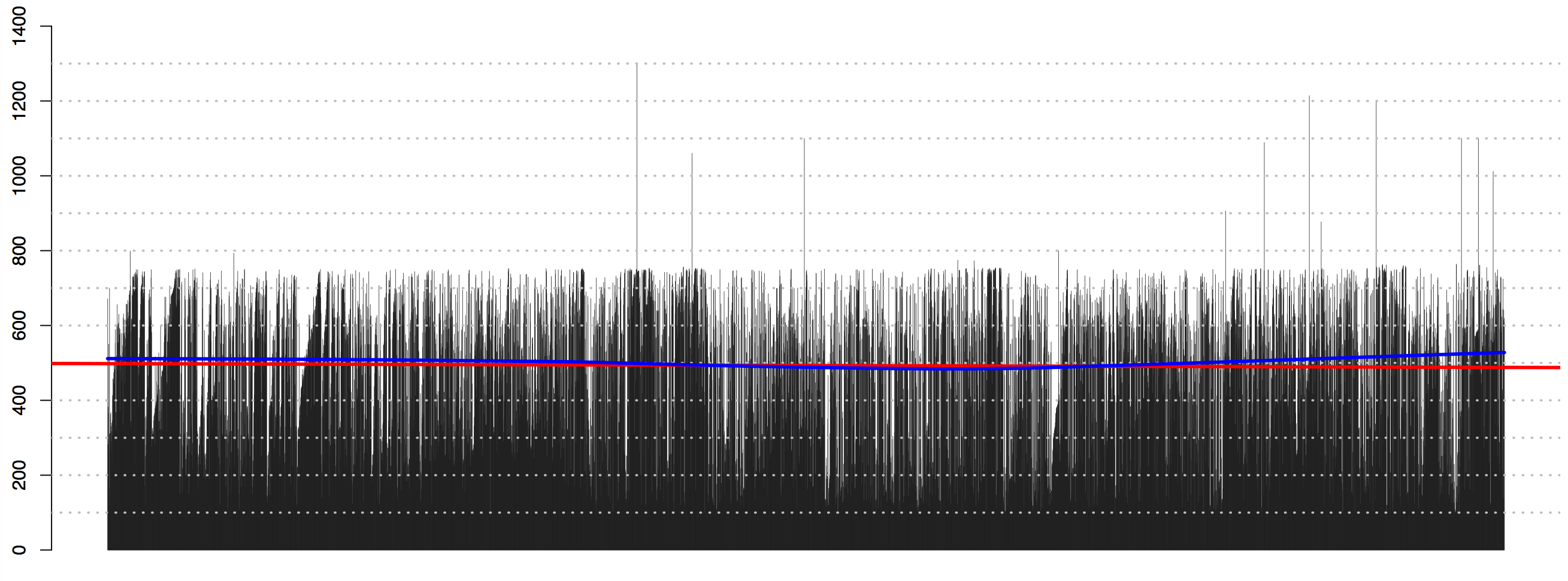
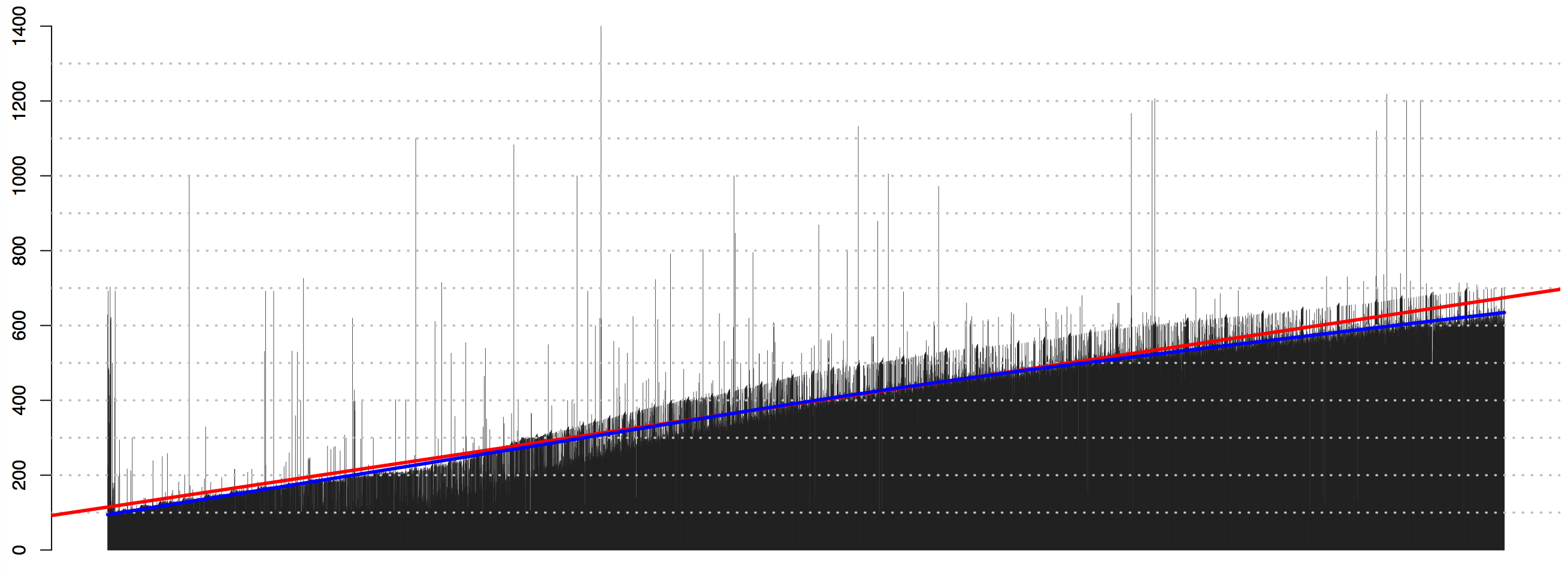
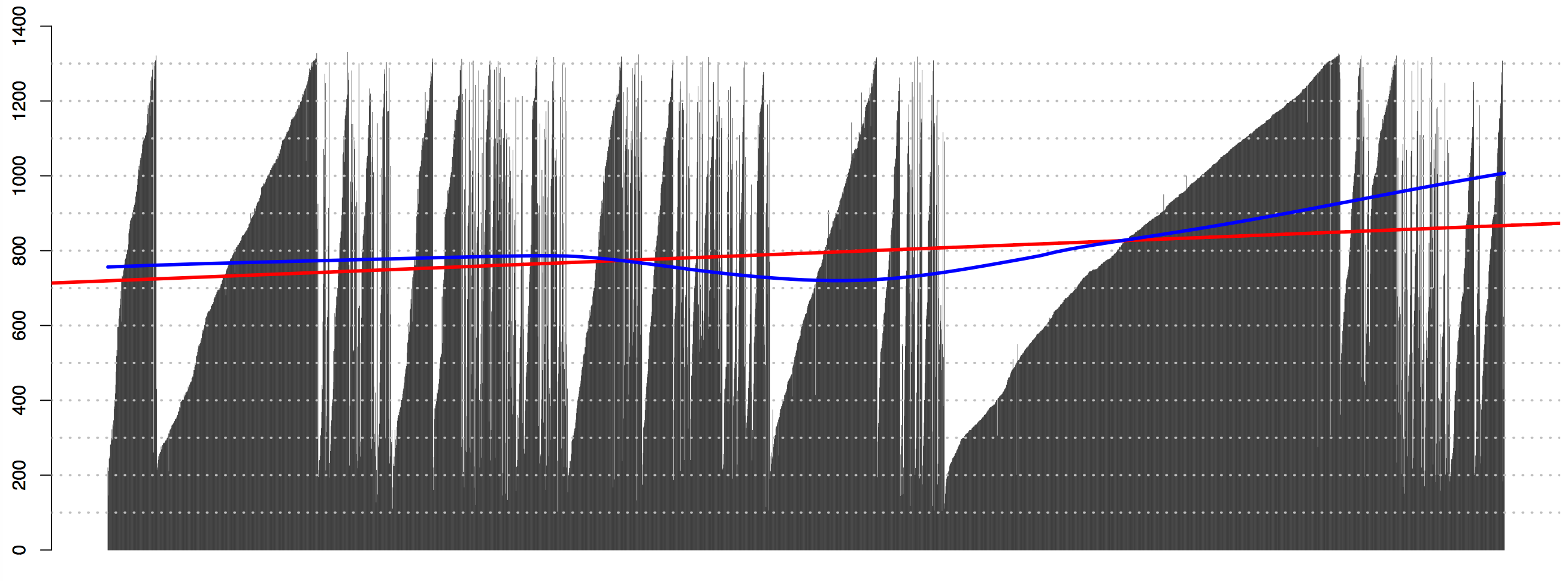
Patterns of date statements distribution across texts—in other words, if we graph dates in the order they occur in a text—can also tell us a lot about the structural organization of books. As the illustrations below show, alphabetical and chronological structures have distinct visual patterns. Such patterns can be helpful in assessing new corpora and identifying texts relevant for specific research purposes. Different routines can be developed for the identification and analysis of texts of other forms and genres.
Note on graphs below: Each line represents a date statement, where the length of the line corresponds to the year that a date statement refers to. The left side of each graph is the beginning of the book; the right one—its end. Regression analysis—here visualized with the red line for linear regression, and the blue one for LOWESS regression—can be used for identifying the patterns of distribution without graphing. (1st-century dates were removed to make patterns more clear.)
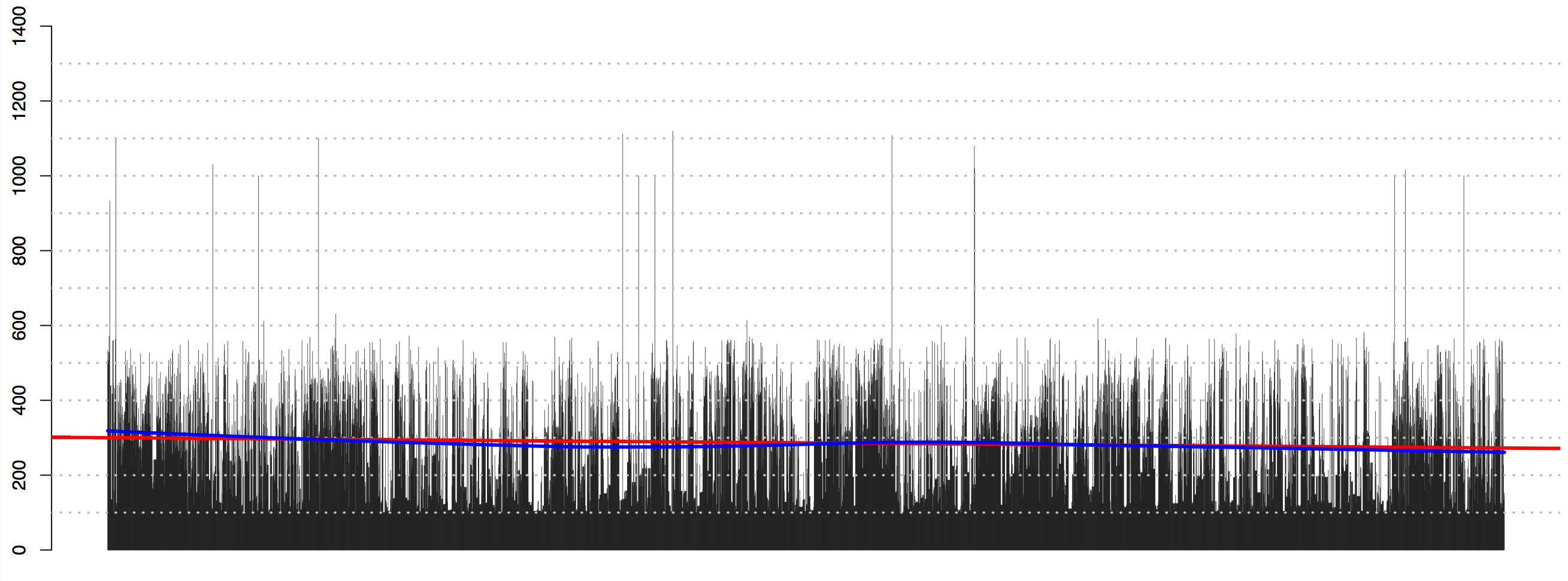
Concluding remarks
One thing that must be voiced is that if we had a corpus properly prepared by scholars and for scholars that would include robust metadata and texts tagged into logical units, the results of such an experiment would have been significantly more precise and reliable, not to mention that such a corpus would also allow to run a number of other exploratory experiments. To put it differently, we—scholars who study the premodern Islamic world, and who are actively using collections developed in Arab countries and Iran for non-academic purposes (and let’s be honest, most of us do)—must invest time and effort into the development of a digital library that would allow all of us to engage in methodologically novel research. Such a library would also allow to build on the each other’s research more consistently, which would also help to forge a new collaborative culture that will be beneficial to the entire field.
Appendix I: Exploring coverage of historical sources
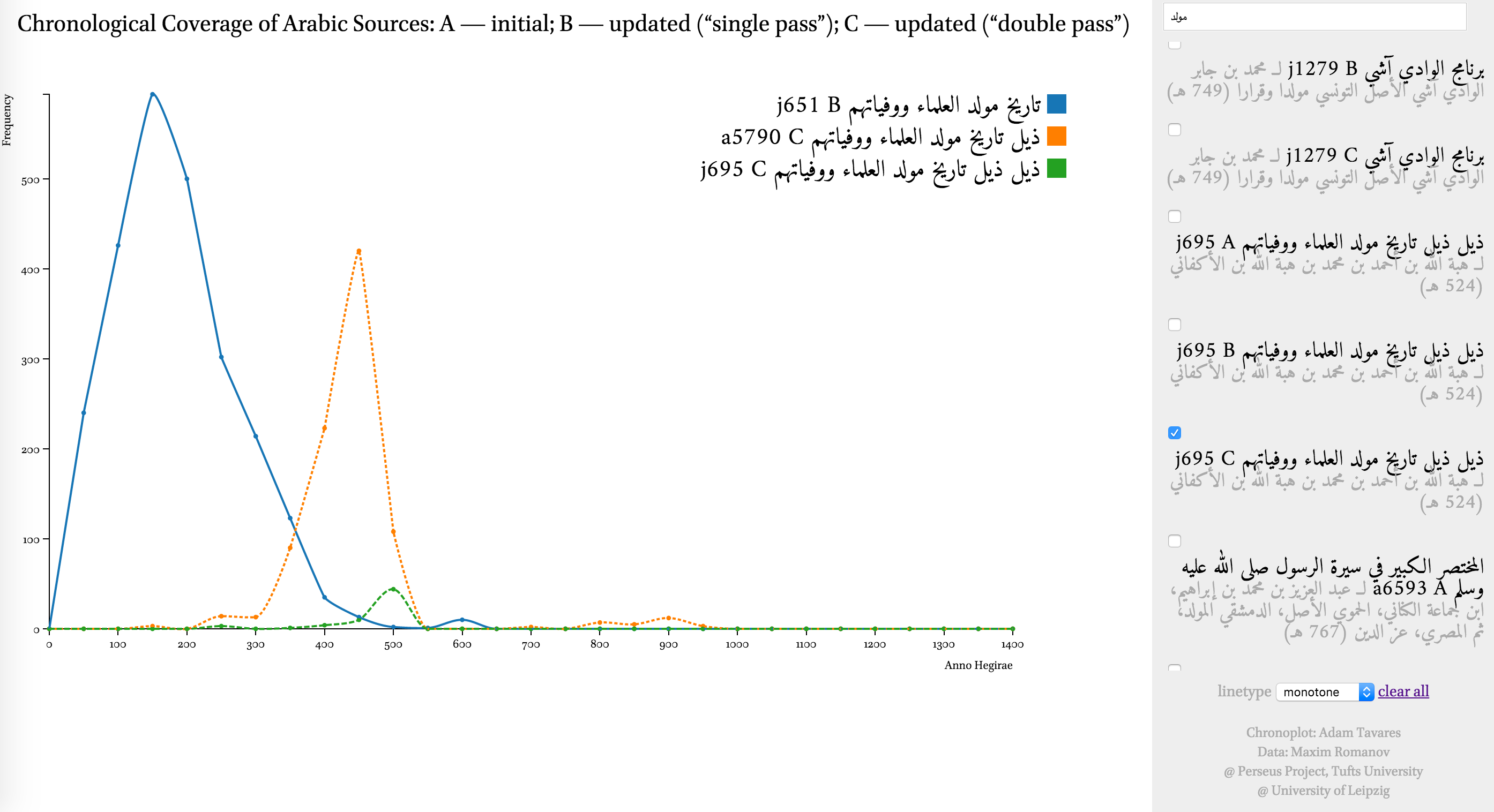
You can explore the chronological coverage of historical texts using Chronoplot (it may take a moment to load). Current data includes about 3,000 texts (including versions of the same text from different libraries). Keep in mind the following:
- Each text has a unique identifier: letter + number, where the former refers to a collection, and the latter—to the number of a text in that collection:
- j — al-Ǧāmiʿ al-kabīr;
- a — al-Maktabaŧ al-Šāmilaŧ;
- i — al-Maktabaŧ al-Šīʿiyyaŧ.
- Each text has three variations of date statement distribution. (Consider comparing variations for the text with the same identifier.) Texts of the same title from different collections occasionally give different distributions (especially when electronic texts are based on different printed editions).
- A — unmodified dates (“1st century problem”);
- B — updated dates (“single pass”);
- C — updated dates (”double pass”)
- Selector (right) can be used to select titles for graphing their chronological coverage. Choosing multiple titles will allow to compare their coverages.
- Filter (right top) can be used to find specific titles: type a part of an author’s name or a book’s title, and the list will be filtered to show only items that have your keywords.
- Linetype (right bottom) is a drop-down menu that offers several ways graphing the results. The most appropriate linetype for displaying chronological coverage is “step-before,” since it shows the frequencies of date statements per 50-year periods in the most clear manner. However, this works well only for single texts. For comparative purposes “monotone” seems to be a better option.
Appendix II: Exploring coverage of historical periods
The table below lists sources by frequencies of date statements. Like Chronoplot, this table also has three variations of each text (A, B, C). Since variations A, B, and C differ only in how dates are distributed across periods, the initial table shows only variation A. Selecting a particular century will show only texts (with variations) that have dates for those periods.
Metadata on texts is not always complete. The missing information may be available online—where applicable, links to the online manifestations of texts are provided.
Leave a comment